|
© 1999-2003, Flemming Koch Jensen
Alle rettigheder forbeholdt |
|
Assembler
|
|
I tidernes morgen (ca. 1945-50) bestod programmering i at tænde og slukke for en række af kontakter i en hensigtsmæssig rækkefølge. Det var ren binær programmering. | ||
Mekanisk klaver |
Det blev man naturligvis hurtig træt af og man søgt at kommunikere med elektronhjernen på en mere menneskevenlig måde. Man begyndte at bruge papirstrimler og papkort; hvor små huller gav det ud for tændt eller slukket. I indlæseenheden var der en række kontakter der passede til hullerne og hullernes mekaniske påvirkning eller mangel på samme, tændt og slukkede for kontakterne. Princippet var taget fra det mekaniske klaver. | |
|
Man brugte dog stadig direkte at angive den binære kode der udgjorde programmet. Denne form for programmering, hvor man direkte angiver programmets kode, kaldes maskinkode programmering. | ||
Symbolsk maskinkode |
I stedet for at angive den direkte binære kode for et program, gik man over til at bruge bogstavsforkortelser for de enkelte koder i programmet. Man lavede dertil et program der oversatte den symbolske maskinkode til rigtig maskinkode. | |
|
Også dette var trættende at arbejde med; hvorfor man rafinerede metoden yderligere. Man brugte stadig symbolske navne, men man lod nu oversætter-programmet selv tage en række beslutninger som var uden betydening for programmet funktion. | ||
|
Det var f.eks. spørgsmålet om hvor i computerens hukommelse man skulle gemme konkrete data. Det er naturligvis uden betydning hvor i lagret de enkelte data befinder sig, blot programmet ved det! | ||
Symbolske navne |
Man indførte også en række hjælpemidler, der tillod en mere symbolsk udtryksform når man programmerede. Hvis man f.eks. brugte den samme konstant flere gange i et program, kunne man definere et symbolsk navn som synonym for denne værdi, og i stedet bruge navnet rundt omkring i programmet. | |
|
Som vi skal se i senere kapitler indførte man også mange andre hjælpemidler. | ||
Assembler |
Denne form for programmering, der er et raffinement af symbolsk maskinkode, kaldes assembler. Inden vi går over til assembler, vil vi kort se på hvad maskinkode er, og hvordan et program kan ligge i lagret. | |
|
1. Maskinkode | ||
|
Når programmer skal kunne lige i lagret, må de være beskrevet i form af koder, der fortæller CPU'en hvad den skal gøre. CPU'en har et specielt register, generelt kaldet program-pointeren eller instruktions-pointeren, der holder rede på, hvor i lagret og dermed i programmet CPU'en er kommet til. | ||
|
CPU'en arbejder ved hele tiden at hente en kode, kaldet en instruktion, fra lagret, udføre den, hente den næste instruktion, udføre den osv. Maskinkodeprogrammer har derfor et meget sekventielt forløb. De kører ligesom en papirstrimmel. Som vi senere skal se, er der forskellige muligheder for at ændre på forløbet så vi kan foretage valg og gentagelser. | ||
|
Lad os se et eksempel på hvorledes en maskinkode instruktion kan se ud. Følgende instruktion kopierer værdien, der ligger i BX over i AX. Den er binært: | ||
|
| ||
|
Hvilket svarer til 89D8H . Instruktionen er opdelt i en del der fortæller, at et register skal kopieres til et andet register (10001B) og en del der fortæller CPU'en hvilket registre der er tale om (00111011000B). | ||
|
Vi vil ikke gå dybere ind i maskinkode, da det er et område man meget sjældent kommer i kontakt med. | ||
DEBUG.COM |
Når man vil studere maskinkode og symbolsk maskinkode på PC'ere kan man bruge et lille program, der er en del af DOS. Dette program er DEBUG.COM. Programmet giver muligheder for at inspicere PC'ens lager, indtaste symbolsk maskinkode og køre programmer. Man kan også prøvekøre små assemblerprogrammer vha. DEBUG. Mht. anvendelsen af DEBUG henvises til anden litteratur. | |
|
2. Segmenter | ||
|
Vi har tidligere understreget at en computer arbejder med proces og data. Denne todeling finder man derfor også i assembler programmer, hvor man opdeler koden i en datadel og en kodedel. Disse dele kaldes i assembler for segmenter: datasegmentet og kodesegmentet. | ||
|
Til at holde styr på disse to dele bruger CPU'en to register, der fortæller hvor i lagret disse segmenter befinder sig. | ||
|
Før vi begynder at beskrive mekanismerne omkring disse segmenter, vil vi se på lager-topologien. | ||
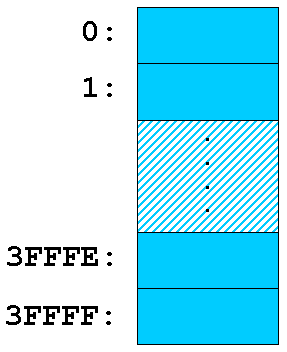
Figur 1:
|
| |
Cellerne har hver en adresse |
Lagret er opbygget som en meget lang række af celler, der hver er i stand til indeholde en byte. Hvis man f.eks. har et lager på 4 MB, er der 4.194.304D lagerceller efter hinanden. Disse celler er nummerede fra 0 til f.eks. 4.194.303D. Disse grænser angives naturligvis i hex: 0 til 3FFFFFH . Nummeret på en celle kaldes dens adresse. Ved at lægge en værdi i en celle og huske adressen kan man senere vende tilbage og finde værdien igen. | |
Lokation |
Cellerne i lagret kaldes generelt for lokationer. Betegnelsen lokation er en mere fleksibel betegnelse, der også kan bruge på words og dwords i lagret. Når man arbejder med words og dwords er CPU'en mest effektiv hvis de ligger på lige adresser i lagret, dvs. hvor cellens adresse er et lige tal. | |
|
Når CPU'en derfor skal holde rede på hvor datasegmentet og kodesegmentet er, bruger den adresserne på de steder i lagret hvor disse segmenter begynder. | ||
Segment starter ved paragraf |
I denne forbindelse kommer der en lille urenhed, fra den måde Intel har lavet det på. Det drejer sig om, at segmentregistre kun er på 16 bits, mens man på det tidspunkt segmenterne bliv indført, gerne ville kunne adressere 1 MB. Med 16 bits er man kun i stand til at adressere 216 = 65536 bytes. Man mangler 4 bit for at nå op på de 20 der skal til for 1 MB. Da man ikke arbejder med så mange segmenter, er det ikke væsentligt at kunne placere et segment på en hvilken som helst lokation i lagret. Derfor vedtog Intel, at værdierne i segmentregistrene skulle fortolkes som om der var fire 0-bit efter. Ved at anlægge denne fortolkning kan segmenter kun starte fra adresserne 0H, 10H, 20H, osv. Da segmentregistre altid slutter med et 0 i hex bruges man ofte at sætte dette 0 i kantede parenteser f.eks. 34A1[0]H . De stykker i lagret som er på 10H bytes, og som i lagret følger de mulige segment-startadresser, kalder man paragrafer. | |
|
Datasegment registeret hedder DS, og kodesegment registeret kaldes CS. | ||
Segmenter er højest 64 KB |
Når man angiver lokationer i segmenterne bruger man ud over segment-registret også et offset der angiver adressen relativt i forhold til starten af segmentet. offsets er også på 16 bit, og man kan derfor ikke have et segment på mere end 64 KB. | |
|
Man kan enten angive offsets direkte, eller vha. et register som indholder offset'et. Disse offset-registre er default tilknyttet bestemt segmentregistre. For DS drejer det sig om SI, og for CS er det IP. Man ændrer aldrig selv IP. Der findes et ekstra segmentregister ES som man normalt kan bruge frit. ES har tilknyttet DI. | ||
|
3. Instruktioner | ||
Kode-segmentet |
I kodesegmentet befinder selve programmet sig. Et program består i assembler, såvel som i maskinkode, af en række instruktioner. Instruktioner kan have 0, 1, 2 eller 3 argumenter. Disse argumenter står efter instruktionen og angiver hvilke data der indgår i operationen. Det kunne f.eks. være flg. instruktion, der kopierer værdien fra BX over i AX. | |
|
| ||
Højre mod venstre |
Man ser at "retningen" mellem argumenterne altid er fra højre mod venstre. Det er værdien i det højre register, der kopieres over i det venstre register. Ved 2 eller 3 argumenter til en instruktion, adskilles disse med komma. | |
|
4. Skabelonen | ||
COM-program |
Da assembler på Intel-CPU'er i virkeligheden er en uoverskuelig rodebunke, vil vi altid bruge en bestemt skabelon til vores assembler programmer. Den resulterer i en .COM file. I en .COM file er CS og DS sat til den samme værdi og data- og kodesegment er derfor sammenfaldende. | |
Source 1:
|
| |
|
Man skal være opmærksom på, at de extendede arbejdsregistre EAX, EBX, ECX og EDX ikke står til rådighed med denne forenklede skabelon. | ||
|
Repetitionsspørgsmål | ||
1 | Hvad er symbolsk maskinkode? | |
2 | Hvad er assembler? | |
3 | Hvordan afvikler CPU'en et program? | |
4 | Hvad er et segment? | |
5 | Hvad er en lokation? | |
6 | Hvad er en paragraf? | |
7 | Hvorfor starter alle segmenter ved en paragraf? | |
8 | Hvad er den maksimale størrelse af et segment? | |
9 | Hvad kendetegner et COM-program? | |
|
Svar på repetitionsspørgsmål | ||
1 | Maskinkode angivet med forkorterlser for hver maskinkode. | |
2 | En udbygning af symbolsk maskinkode, hvor der ikke nødvendigvis er en 1-1 sammenhæng mellem assembler instruktioner og maskinkode. | |
3 | En maskinkode instruktion efter den anden. Den indlæser en instruktion, udfører den, indlæser den næste, udfører den osv. | |
4 | Et segement er en del af et program. Det kan være en datadel eller en kodedel. | |
5 | Et sted i lagret, angivet med en adresse. | |
6 | En adresse som 16 går op i. | |
7 | Fordi der ikke er bits nok i et segmentregister til at adressere 1 MB, som er det man ønsker at kunne adressere. | |
8 | 64 KB. | |
9 | At datasegment og kodesegment er sammenfaldende. | |
|
|