|
SQL (Structured Query Language) anvendes til at arbejde med databaser. SQL er opbygget med sætninger, der en efter en sendes til databasen, og giver den instrukser om hvad den skal gøre. Sætningerne kan grundlæggende inddele i to katagorier, alt efter hvad man ønsker at gør: Data Definition Language (DDL) og Data Manipulation Language (DML). |
|
Data Definition Language er den del af SQL der anvendes til at opbygge databasen med tabeller og relationer, og Data Manipulation Language er den del af SQL der anvendes til at arbejde med de data der befinder sig i databasen. |
|
Når man introduceres til arbejdet med databaser,
vil man som oftest skulle starte med at opbygge databasen fra grunden. Vi vil derfor først studere mulighederne i DDL,
da det er dem man får brug for, til at lave databse og tabeller. |
| Kommentarer |
Inden vi går igang, skal der lige indskydes en kommentar — vedrørende kommentarer! Man skriver kommentarer enten som blok-kommentarer, som det kendes fra Java/C#, dvs: /* <kommentar> */, hvor der må optræde linieskift i kommentaren. Man kan også lave linie-kommentarer som det kendes fra Java/C#, men syntaksen er en anden! I stedet for at starte med: "//", startes der med: "--" (i.e. to gange minus). |
|
1. Data Definition Language |
|
1.1 Databaser |
|
Man kan oprette og arbejde med databaser i Management Studio. F.eks. kan man lave en database ved at højre-klikke på Databases i Object Explorer, og vælge New Database. Man kan dernæst indtaste navnet på databasen, og man trykke OK (vi har ikke behov for at indstille andre ting). Dermed er databasen oprettet og man kan nu begynde at oprette tabeller etc. |
|
Det er alt sammen meget godt, men vi vil gøre det på en anden måde — vi vil lave det hele med SQL! Det vil vi primært gøre for hurtigt at kunne retablere vores databaser, når vi har "ødelagt" dem ved at eksperimentere med dem. I den forbindelse opbygger vi ét langt script, der starter med at oprette databasen og giver den et indhold; hvorefter vi placerer en eller flere SQL-sætninger der udfører vores "eksperiment" — et eksempel, eller løsningen af en opgave. |
|
For at kunne opbygge et sådant script, skal vi bruge et tekst-dokument som Management Studio vil betragte som et SQL-script. Det får vi ved at klikke på New Query i toolbaren (længst til venstre i toolbaren). Dette giver os en tekst-editor; hvor vi kan opbygge et SQL-script. |
|
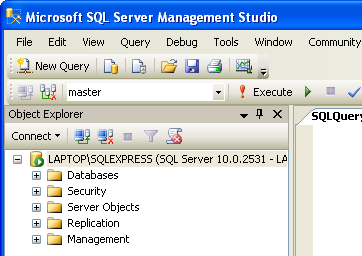
I øverste venstre side af Management Studio, vil man nu se en dropdown; hvor der står master (der kan også stå andet, men master er normalt default). Hvis der ikke står noget i dropdown, er det fordi tekst-editoren ikke har fokus (i.e. at cursoren ikke er placeret i tekst-editoren). |
Figur 1:
Valg af aktuel database |
 |
| Valg af database |
Denne dropdown styrer hvilken database vores script vil blive udført på. Hvis man udfører en række sætninger, men ikke kan forstå hvorfor de ikke synes at have nogen effekt på ens database, kan det skyldes, at en forkert database er valgt i denne dropdown. I så fald, kan man håbe at den database, der var valgt, ikke har taget væsentlig skade af det script man har udført på den! |
|
Sådan som vi vil lave vores scripts, er valget af database en ting vi foretager i scriptet, så ovenstående er kun en ting der er rar at vide! |
|
Uanset hvilken database, der er valgt som den aktuelle database for vores script, kan vi oprette en ny database med: |
| Oprettelse af database |
CREATE DATABASE <database-navn>
|
|
F.eks.: |
|
|
|
Bemærk, at alle sætninger i et script skal afsluttes med semi-kolon, ligesom det kendes fra diverse programmeringssprog. Det er en detalje vi vil udelade når vi taler om de enkelte SQL-sætninger, da den kun forekommer i scripts. Skulle man glemme semi-kolon i ens scripts, endog utallig steder, synes det ikke at give nogen fejl — Management Studio forstår det alligevel — men generelt er det nok en dårlig vane at udelade dem, da man derved gør sig afhængig af den applikation der udfører scriptet. |
|
Ligesom vi kan vælge mellem at oprette en database med Management Studio eller med en SQL-sætning, kan vi også vælge at anvende en bestemt database i SQL. Det gøres med: |
| Valg af aktuel database |
|
|
F.eks.: |
|
|
|
Udfører man et script,
hvor der optræder en USE-sætning, vil dropdown'en efter udførelse af scriptet være indstillet til den pågældende database. |
| Sletning af database |
Man har også mulighed for at slette en database, enten ved at højre-klikke på den i Management Studio og vælge Delete, eller med SQL-sætningen: |
|
DROP DATABASE <database-navn>
|
|
F.eks.: |
|
|
|
Vi kan nu samle ovenstående i et script, der kan bruges til at oprette og eksperimentere med en database: |
| Script-skabelon |
USE master;
IF DB_ID( 'PersonDB' ) IS NOT NULL
DROP DATABASE PersonDB;
CREATE DATABASE PersonDB;
GO
USE PersonDB;
/* diverse andre SQL-sætninger */
|
|
Vi har her tilføjet et par praktiske detaljer. |
| Kan ikke slette aktuel database |
Det første vi gør er at skifte til master-databasen, før vi (evt.) sletter SkoleDB-databasen. Master-databasen indeholder oplysninger om de andre databaser på serveren, men det er ikke derfor vi vælger at skifte til den — det skyldes at vi ikke kan slette en database, hvis den er i brug! Hvis SkoleDB-databasen er valgt som den aktuelle database i Management Studio (i.e. at den står som valgt i dropdown'en), vil vi ikke kunne slette den, fordi den rent teknisk er i brug. Formålet med at skifte til master-databasen er derfor udelukkende at skifte til en database vores script aldrig vil slette, og dermed (evt.) frigøre den database (i dette tilfælde SkoleDB) som vi vil slette. |
| Om databasen eksisterer |
Vi forsøger kun at slette databasen, hvis den eksisterer. Laver vi ikke dette check i forbindelse med DROP DATABASE vil vi få en fejl, hvis den ikke findes. Fejlen vil ikke have opsættende virkning på resten af scriptet, men vi vil gerne undgå at den "støjer" i outputet fra udførelsen af scriptet. Man kan så diskutere hvad der er grimmest — if-sætningen, eller fejlmeddelelsen! |
| GO |
Efter CREATE DATABASE er der tilføjet en linie med GO. GO er en besked til Management Studio (der udfører scriptet) om at de foregående SQL-sætninger skal udføres. Man kan sammenligne det lidt med flush i forbindelse med buffere. GO skal stå på en linie for sig selv, og den skal ikke efterfølgende af semi-kolon, da den ikke er en SQL-sætning. Man kan plastre sine scripts til med GO over det hele, men vi vil nøjes med at bruge GO hvor det er nødvendigt (det blobber syntaksen). Hvis vi ikke anvender GO i denne situation, vil USE-sætningen fejle, med en besked om at databasen ikke eksisterer. |
| Tekststrenge |
En sidste ting, man bemærker ved ovenstående script, er teksstrengen: PersonDB, der optræder som parameter til DB_ID-funktionen. Tekststrenge i SQL skrives ikke i anførselstegn, som man kender det fra diverse programmeringssprog, men mellem apostrofer. |
|
1.2 Tabeller |
|
Ligesom med selve databasen, kan vi også oprette og slette tabeller. Da vi i forbindelse med vores script starter med en nyoprettet, og dermed tom database, behøver vi ikke at slette nogen tabeller, men for fuldstændighedens skyld vil vi alligevel se hvordan dette gøres. |
| Sletning af tabel |
|
|
F.eks.: |
|
|
| Betinget sletning |
Igen vil dette give en fejlmeddelese hvis tabellen ikke findes, og vi kan derfor ønske at gøre det betinget af at tabellen eksisterer. Dette gøres med følgende: |
|
IF OBJECT_ID( 'person', 'U' ) IS NOT NULL
DROP TABLE person
|
|
Her refererer 'U' til at der er tale om en "user table" — men kønt er det ikke. |
|
Som nævnt behøver vi ikke anvende DROP TABLE i vores scripts, når vi starter med en nyoprettet database. |
|
Vi opretter en tabel med følgende konstruktion: |
| Sletning af tabel |
CREATE TABLE <tabel-navn> (
/* erklæring af attributter etc. */
)
|
|
De anvendte linieskift øger læsbarheden, specielt når vi begynder at give erklæringen mere indhold, men de er som andre linieskift i SQL valgfrie. |
|
Indholdet er i første række en opremsning af de enkelte attributter og deres egenskaber — primært navn og type. |
|
Vi kunne f.eks. oprette en person-tabel med: |
|
CREATE TABLE person (
id int,
navn nvarchar(25),
gade nvarchar(20),
nr int,
post_nummer int,
alder int
)
|
|
I modsætning til de fleste moderne programmeringssprog (e.g. Java, C#) er typen efterstillet navnet, men ellers ligner det meget erklæringen af en række variable. |
|
1.2.1 Navne |
| Navne-konvention |
SQL er ikke case-sensitive (skelner ikke mellem store og små bogstaver), og der er ikke nogen etableret konvention for hvordan man skriver attribut-navne etc. Samtidig har SQL Server (tilsyneladende) ikke problemer med de danske bogstaver 'æ', 'ø' og 'å'. Det giver rimelig frit spil mht. hvad man vælger, men vi vil her forholde os meget konservativt, vel nærmest "retro", til navngivning. Det skyldes at SQL er et gammel sprog, der går helt tilbage til 70'erne, og man aldrig ved hvor gammel en database, man kan risikere at komme til at arbejde med. Den konvention der anvendes her, er at der kun bruges små engelske bogstaver, og at der ved sammensatte navne anvendes '_' (underscore) i stedet for "camel" (stort start-bogstav for hver ny ord i et sammensat navn). Man ser et eksempel på sidst nævnte i forbindelse med attributten: post_nummer. Mht. tabel-navne vil vi anvende en tilsvarende konvention, og bruge ental — f.eks. vil vi ikke kalde en tabel: personer, men: person. Man kunne have valgt andre konventioner, og man skal være velkommen til det, men det er vigtigt at have en vis ensartethed i de ting man laver — så er de nemmere at arbejde med. |
|
1.2.2 Typer |
| Tekststrenge |
Mht. typer, kan det afhænge meget af hvilken database server man bruger. Vi har her brugt nvarchar(n) for tekststrenge; hvor vi har anført en maksimal længde n. Det betyder f.eks. for navn, at det kan være en tekststreng på mellem 0-25 tegn, men aldrig mere! Grunden til at det ikke bare er frit (som vi kender det fra programmering), er at data i en database ligger i filer. Hvor effektive disse filer tidsmæssigt er at arbejde med, afhænger af hvor nemt det er at finde rundt i dem. Jo mere man skal sige om den pladsmæssige størrelse af forskellige ting, jo hurtigere bliver det. En anden mulighed er at bruge: nchar(n). I så fald er teksstrengen altid netop n tegn; hvilket til gengæld kan være upraktisk at arbejde med, med mindre det netop er tilfældet. Det kan f.eks. bruges i forbindelse med initialer, produktkoder etc., hvor længden altid er den samme. Bruger man det ellers, må man indsætte/fjerne overflødige mellemrum, der skal til for at opnå den præcise længde! |
| Uden 'n' |
Man vil uvægerlig støde på varchar(n) og char(n), altså de tilsvarende typer uden det foranstillede 'n'. Disse varianter understøtter ikke Unicode, men enkelt-byte tegn, dvs. ASCII. 'n' står forøvrigt for "national", hvilket måske er lidt perifært at relatere til Unicode. |
| Tekst |
Skal man repræsentere større stykker af tekst, f.eks. et debat-forum, der opbevares i en database; hvor de enkelte indlæg kan have vidt forskellig og betydelig længde, anvender man typen: ntext. Tilsvarender type: text, der igen ikke understøtter Unicode. Attributter af denne type kan indeholde op til 1 Giga tegn (i.e. ca. 1 milliard tegn), så det rækker til det meste! Man skal naturligvis være opmærksom på at dette koster på effektiviteten, mht. anvendelsen af databasen. |
| Numeriske typer |
Mht. de numeriske typer er det mere enkelt — de har naturligt en fast størrelse! Vi har her brugt int, i værdimængde svarer til int som vi kender det fra Java/C#, men vi kunne også have valgt tinyint (byte), smallint (short) eller bigint (long), der svarer til de i parantes anførte typer i Java/C#. Mht. kommatal kan vi anvende float (double) og real (float), der svarer til de i parantes anførte typer i Java/C#. |
| Boolske værdier |
Der findes ikke nogen type til boolske værdier. Det nærmeste man kommer det er typen bit, men der er en tradition for at man i databaser selv gemmer dem som værdierne 0 (false) og 1 (true), som man finder anledning til at gøre det. Har en tabel flere boolske attributter, og man anvender typen bit, vil de file-mæssigt blive samlet i en byte; hvilket kan have pladsmæssig betydning, alt efter hvor stor ens database er. |
| Binær data |
En attribut kan også indeholde binær data. I så fald anvender man typen: binary(n) eller varbinary(n), alt efter om n er en fast længde i bytes, eller en maksimal grænse, som man kender det fra tekststrenge. |
|
1.2.3 Primær nøgler |
|
Man kan anføre at en attribut er primær nøgle på én af to måder. Enten: |
| Ved attributten |
CREATE TABLE person (
id int PRIMARY KEY,
navn varchar(25),
...
)
|
|
eller: |
| Til sidst |
CREATE TABLE person (
id int,
navn varchar(25),
...
alder int,
PRIMARY KEY (id)
)
|
| Sammensat primær nøgle |
Fordelen ved den første, er at alle oplysninger om id er samlet et sted, mens ulempen er at man ikke kan anføre en sammensat nøgle på denne måde — det kan kun gøres på den anden måde, hvor spørgsmålet om hvad der er primær nøgle er en supplerende oplysning til attribut-listen. Ved en sammensat nøgle vil syntaksen være: |
|
CREATE TABLE person (
id int,
navn varchar(25),
...
alder int,
PRIMARY KEY (id, navn)
)
|
|
hvilket naturligvis vil være en mere end tvivlsom nøgle i praksis! |
|
Det ses ofte, at man generelt anvender sidst nævnte placering, da den ikke har først nævntes begrænsinger. |
|
1.2.4 Null værdier |
| Default |
Hvis man ikke skriver noget, vil det være tilladt en attribut at have null-værdier. Man kan forbyde dette ved at anføre NOT NULL efter efter erklæringen af den enkelte attribut. F.eks.: |
|
CREATE TABLE person (
id int,
navn nvarchar(25) NOT NULL,
gade nvarchar(20),
nr int,
post_nummer int,
alder int
)
|
|
hvor vi insisterer på at navnet skal være i tabellen, mens adresse og alder ikke er strengt nødvendige. |
|
Bemærk, at det er redundant at anføre NOT NULL for en primær nøgle, da dette i forvejen altid gøre sig gældende for en sådan. |
|
1.2.5 Auto-genererede værdier |
|
Typisk i forbindelse med primær nøgler, kan man ønske at disse bliver automatisk genereret af databasen, så man er sikre ikke at få problemer med, at de er unique. Dette gøres ved at anføre IDENTITY |
|
CREATE TABLE person (
id int IDENTITY,
navn nvarchar(25),
...
)
|
|
hvor de auto-genererede værdier for id, ved indsættelse af en række person vil bliver: 1, 2, 3 ... |
| Andre værdier |
Ønsker man andre værdier, kan man enten anvende: IDENTITY(n), hvor n er den første værdi. F.eks.: IDENTITY(5), der vil give værdierne: 5, 6, 7 ..., eller: IDENTITY(n, m); hvor man også kan bestemme med hvilke spring værdierne skal komme. F.eks.: IDENTITY(5, 3), der vil give værdier: 5, 8, 11, ... |
|
Bemærk, IDENTITY kan også bruges ved attributter der ikke er primær nøgler! |
|
2. Data Manipulation Language |
|
Vi vil fokusere på de fire grundlæggende SQL-sætninger: INSERT, SELECT, DELETE og UPDATE, i nævnte rækkefølge. Man kunne måske mene at SELECT var den simpleste at starte med (da den ikke ændrer databasen), men vi vil starte med INSERT, da vi i forbindelse med vores SQL-script ønsker at give vores database (i.e. tabeller) et data-indhold. |
|
2.1 Insert |
|
Vi har en database med tabeller, nu skal de have et indhold. Det gøres med INSERT-sætningen, der findes i to varianter. |
|
2.1.1 Simpel indsættelse |
|
Ved simpel indsættelse anfører vi alle attributternes værdier, i den rækkefølge de optræder i erklæringen af tabellen. På den måde behøver vi ikke anføre attributternes navne i forbindelse med INSERT-sætningen. F.eks.: |
| Simpel INSERT |
INSERT INTO <tabel-navn> VALUES ( <værdi-1>, <værdi-2>, ... )
|
|
F.eks.: |
|
INSERT INTO person VALUES ( 1, 'Anders And', 'Paradisæblevej', 4, 7430, 32 )
|
|
Hvis en attribut, f.eks. id, er auto-genereret, må vi ikke anføre nogen værdi, og den udelades derfor i listen: |
|
CREATE TABLE person (
id int IDENTITY,
navn nvarchar(25),
...
);
INSERT INTO person VALUES ( 'Anders And', 'Paradisæblevej', 4, 7430, 32 );
|
|
2.1.2 Med angivelse af attributter |
|
Ønsker vi ikke at anføre værdier for alle attributter, eller ønsker vi at anføre dem i en anden rækkefølge end den de optræder i, i erklæringen af tabellen, skal vi anføre attributternes navn. Dette gøres med følgende variant af INSERT-sætningen: |
| INSERT med attribut-navne |
INSERT INTO <tabel-navn> ( <navn-1>, <navn-2>, ... ) VALUES ( <værdi-1>, <værdi-2>, ... )
|
|
Hvis vi f.eks. kun vil anføre navnet, og udelade de øvrige oplysninger for en person, kan det gøres med: |
|
INSERT INTO person ( navn ) VALUES ( 'Anders And' )
|
|
De attributter der på denne måde vil komme til at mangle værdier, vil få indsat null-værdier. Dette gælder naturligvis ikke hvis de pågældende attributters værdier er auto-genererede. |
|
Vi indsætter lidt flere personer i vores database, og den samlede erklæring af person-tabellen bliver: |
| Den samlede erklæring af person-tabellen |
CREATE TABLE person (
id int IDENTITY,
navn varchar(25) NOT NULL,
gade varchar(20),
nr int,
post_nummer int,
alder int,
PRIMARY KEY (id)
);
INSERT INTO person VALUES ( 'Anders And', 'Paradisæblevej', 3, 7430, 32 );
INSERT INTO person VALUES ( 'Rip And', 'Paradisæblevej', 3, 7430, 10 );
INSERT INTO person VALUES ( 'Rap And', 'Paradisæblevej', 3, 7430, 10 );
INSERT INTO person VALUES ( 'Rup And', 'Paradisæblevej', 3, 7430, 10 );
INSERT INTO person VALUES ( 'Andersine And', 'Viol Allé', 8, 7430, 29 );
INSERT INTO person VALUES ( 'Onkel Joakim', 'Bakken', 1, 7400, 72 );
|
|
2.2 Select |
|
SELECT-sætningen laver et data-udtræk fra databasen. |
|
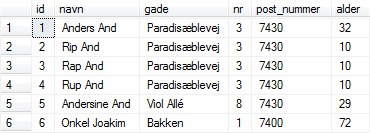
Den mest simple SELECT-sætning laver et udtræk af alle oplysninger fra én tabel. F.eks.: |
Figur 2:
Data-udtræk af hele person-tabellen |
|
| |
I forbindelse med at vi opretter databaser med scripts, kan det være nyttigt at afslutte opbygningen af hver tabel, inklusiv data, med en sådan SELECT, da den giver et overblik over, om data er indsat som forventet. |
| Result set |
Man kalder også et data-udtræk for et result set (dk. resultat mængde). Lidt pudsigt, at man her bruger betegnelsen: mængde, da et result set netop ikke skal opfylde mængde-egenskaben: at et element (i.e. en række) højest forekommer én gang. I en tabel i en database, kan der ikke optræde to rækker der er fuldstændig ens, men det kan udemærket forekomme i et result set. Dette gør det f.eks. muligt at se hvor mange forekomster, der er af en given værdi. Vi vil her holde os til betegnelsen "udtræk" (eller "data-udtræk"), da den fungerer bedst i en danske tekst. |
|
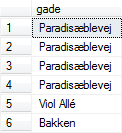
Lad os se et udtræk, hvor de samme rækker forekommer flere gange: |
Figur 3:
gade fra person-tabellen |
|
|
Vi har her valgt kun at få gade-attributten, i stedet for '*', der inkluderer dem alle. Det er dermed lykkedes os at få ens rækker i et udtræk, uanset at disse ikke er særlig interessante — vi kan dog se, at der er fire personer der bor på Paradisæblevej. |
|
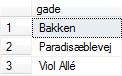
Ønsker man at reducere et udtræk, så der ikke optræder ens rækker, kan det gøres ved at tilføje DISTINCT: |
Figur 4:
Forskellige gader fra person-tabellen |
SELECT DISTINCT gade FROM person
|
|
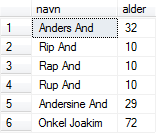
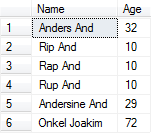
Vi har indtil nu kun valgt at se på en enkelt attribut: gade, men vi kan også vælge flere. F.eks. kan vi vælge både navn og alder: |
Figur 5:
navn og alder fra person-tabellen |
SELECT navn, alder FROM person
|
|
De navne som optræder for kolonnerne i udtrækket stammer fra tabellerne, men vi har også mulighed for at give udtrækkets kolonner egne navne: |
Figur 6:
Alias for kolonne-navne |
SELECT navn AS Name, alder AS Age FROM person
|
| AS, Alias |
AS giver navn og alder hvert deres alias, der vil optræde i udtrækket. Når man arbejder med SQL Server er det ikke nødvendigt at anføre AS, og vi ville derfor have fået det samme resultat, hvis vi havde brugt: |
| Uden AS |
SELECT navn Name, alder Age FROM person
|
|
Vi vil dog bibeholde anvendelsen af AS i forbindelse med aliaser, da den giver er klarere syntaks. |
|
2.2.1 Where |
|
De udtræk vi hidtil har set, har hentet data fra alle rækker i tabellen. Vi kan begrænse hvilke rækker vi ønsker data fra, ved at knytte en betingelse til udtrækket. F.eks. kunne vi indskrænke os til de personer der er over 30 år: |
Figur 7:
Personer over 30 år |
SELECT * FROM person WHERE alder > 30
|
| AND, OR |
Man kan opbygge sammensatte udtryk med AND og OR. F.eks. kan vi finde alle personer mellem 20 og 40 år: |
Figur 8:
Personer mellem 20 og 40 år |
SELECT * FROM person WHERE 20 <= alder AND alder <= 40
|
|
I forbindelse med tekst kan man foretage sammenligninger lighedstegn. F.eks. kan vi finde alle personer der bor på Paradisæblevej:: |
Figur 9:
Personer der bor på Paradisæblevej |
SELECT * FROM person WHERE gade = 'Paradisæblevej'
|
|
Bemærk, at der anvendes enkelt lighedstegn, i modsætning til f.eks. Java og C#, hvor der anvendes dobbelt lighedtegn for lighed. Ved ulighed anvendes <> (i.e. "mindre end eller større end"), men SQL Server accepterer også !=, som det kendes fra Java/C#. |
| LIKE |
Man kan også sammenligne tekststrenge med et mønster. I mønsteret har man to specielle tegn, der optræder som wildcards: procent-tegn ('%') og underscore ('_'). Hvis man f.eks. vil checke om gade starter med "Paradis", kan man bruge: ... gade LIKE 'Paradis%', hvor % står for nul eller flere tegn. Vil man i stedet lade enkelte tegn være "frie" kan man bruge: ... gade LIKE 'P_radisæblevej', hvor andet tegn i tekststrengen kan være hvad som helst, mens det øvrige skal være som anført — f.eks. 'Poradisæblevej', vis der ellers er noget der hedder det!. |
|
Underscore gør det som sagt frit hvilket tegn der skal optræde på en given plads i tekststrengen (der skal dog optræde et tegn), men det er muligt at begrænset hvilke der accepteres. Det gøres med kantede paranteser: [<tegn>]. F.eks. vil: ... gade LIKE 'P[ao]radisæblevej', kun acceptere: "Paradisæblevej" og "Poradisæblevej". Man kan også negere dette med: [^<tegn>]. F.eks. vil: ... gade LIKE 'P[^o]radisæblvej', acceptere alle andre tegn end 'o', og dermed netop ikke: "Poradisæblevej"! |
| NOT LIKE |
Vil man negere hele LIKE-betingelsen, kan man bruge NOT LIKE. F.eks. vil: ... gade NOT LIKE 'Bredgade', acceptere alle tekststrenge undtagen: "Bredgade". |
|
Vi kan få SQL til at tælle antallet af rækker i et udtræk, ved at bruge COUNT-funktionen. F.eks.: kan vi finde antallet af personer der bor på Paradisæblevej med: |
Figur 10:
Antal personer der bor på Paradisæblevej |
SELECT COUNT(*) FROM person WHERE gade = 'Paradisæblevej'
|
|
Som man ser, får den "kunstige" kolonne (den stammer ikke fra tabellen) ikke noget navn, men man kan med AS give den et sådant, hvis det ønskes: SELECT COUNT(*) AS Antal FROM..., eller SELECT COUNT(*) AS 'Antal personer' FROM..., hvis man ønsker at bruge mellemrum i kolonnes navn. |
|
COUNT kan kombineres med DISTINCT, hvis man ønsker at tælle antallet af forskellige værdier for en given attribut. F.eks. kan man tælle antallet af forskellige veje personerne bor på: |
Figur 11:
Antal forskellige gader i person-tabellen |
SELECT COUNT( DISTINCT gade ) AS 'Forskellige gader' FROM person
|
|
SQL har en række af funktioner i stil med COUNT: |
|
- AVG(...): Gennemsnittet af ... den attribut der er anført som parameter.
- FIRST(...): Den første værdi af ...
- LAST(...): Den sidste værdie af ...
- MAX(...): Den største værdi af ...
- MIN(...): Den mindste værdi af ...
- SUM(...): Summen af ...
|
|
Det ligger uden for rammerne af dette kapitel, at give eksempler på anvendelsen af disse funktioner. |
|
2.2.2 Join |
| Kombinere data fra tabeller |
En database består normalt af en række af tabeller, og skal man lave data-udtræk, vil man ofte kombinere data fra flere tabeller. I vores PersonDB-eksempel har vi indtil nu kun haft én tabel: en person-tabel. Vi vil nu indføre en tabel med oplysninger om postnumre, så vi ikke alene kan finde postnummeret for enhver persons bopæl, men også den tilhørende bys navn. Vi vil naturligvis begrænse os, så eksemplet ikke bliver for stort. |
|
Vi indfører en postnummer-tabel med følgende (midtjyske) byer: |
| Erklæringen af postnummer-tabellen |
CREATE TABLE postnummer (
nr int,
byen nvarchar(15) NOT NULL,
PRIMARY KEY (nr)
);
INSERT INTO postnummer VALUES ( 7400, 'Herning' );
INSERT INTO postnummer VALUES ( 7430, 'Ikast' );
INSERT INTO postnummer VALUES ( 7500, 'Holstebro' );
INSERT INTO postnummer VALUES ( 8600, 'Silkeborg' );
INSERT INTO postnummer VALUES ( 8800, 'Viborg' );
|
|
Man bemærker, at vi ikke anvender det nærliggende attribut-navn: by, da det er et reserveret ord i SQL. Vi vælger derfor i stedet det bestemt ental: byen, som det foretrukne alternativ. |
|
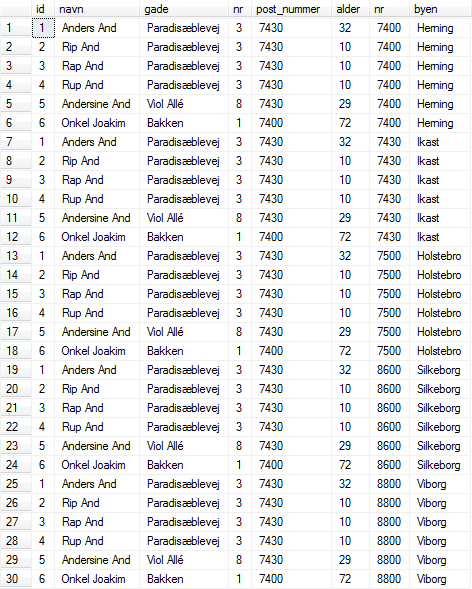
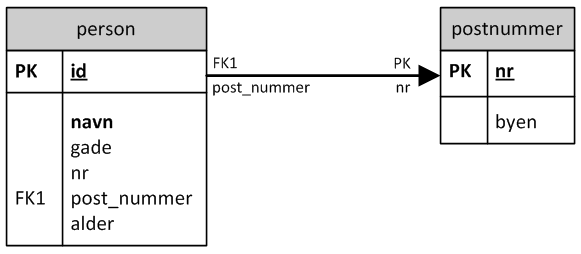
Vores samlede database bliver nu:. |
Figur 12:
PersonDB |
 |
|
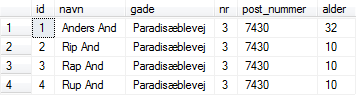
Der findes forskellige former for join operationer, og den første vi vil se kaldes det kartesiske produkt (kaldes også cross join). F.eks. kan vi få det kartesiske produkt af person- og postnummer-tabellen: |
Figur 13:
Kartesisk produkt af person- og postnummer-tabellen |
SELECT * FROM person, postnummer
|
|
En ikke ubetydelig mængde af data! |
|
De første seks kolonner stammer fra person-tabellen, mens de sidste to er fra postnummer-tabellen. Man bemærker, at to af kolonnerne i udtrækket dermed får samme navn: nr, hvilket ikke kan forekomme i en tabel i databasen — men i et data-udtræk kan det godt forekomme. |
|
Ser man igennem rækkerne, bemærker man, at data der ikke har noget med hinanden at gøre optræder i samme række. F.eks. i første række, hvor post_nummer (7430) fra person-tabellen ikke passer med nr (7400) fra postnummer-tabellen. Det skyldes at det kartesiske produkt er kombinationen af alle rækker fra den ene tabel med alle rækker i den anden: i alt 30 rækker (6x5 rækker). |
| Inner join |
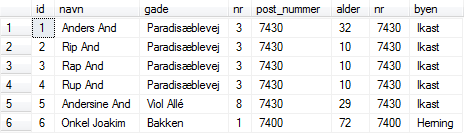
Det kartesiske produkt kan ikke bruges til noget i sig selv, og det er i virkeligheden blot et skridt på vejen til det man i almindelighed mener, når man taler on join — nemlig inner join. For at opnå en inner join, skal vi knytte en WHERE til sætningen så kun rækker hvor tingene passer sammen optræder i udtrækket: |
Figur 14:
Inner join af person- og postnummer-tabellen |
SELECT * FROM person, postnummer WHERE person.post_nummer = postnummer.nr
|
|
De seks rækker i udtrækket, er de rækker i det kartesiske produkt hvor tingene hører sammen — vi bemærker at de to postnumre i hver række er ens. Man kan udvide WHERE-betingelsen (med AND) til kun at udvælge bestemte rækker i dette udtræk. Ud over dette bør udtrækket også begrænse antallet af attributter — specielt den dobbelte forekomst af postnumrene falder i øjnene. |
| Kvalificerede navne på attributterne |
I forbindelse med WHERE-betingelsen, bemærker man at der anvendes kvalificerede navne på attributterne, idet tabel-navnene er foranstillet med punktum. Dette løser problemer med navnesammenfald tabellerne imellem. I vores eksempel har begge tabeller en atribut: nr, og det vil derfor være uklart hvilken der menes, hvis der kun stod: ... WHERE person.post_nummer = nr. Til gengæld er det overflødigt at anføre tabel-navnet foran post_nummer, da kun person-tabellen har en attribut med dette navn. Vi har dog valgt at bruge det begge sted for at bevare balancen i udtrykket. |
|
I stedet for at opbygge en inner join med en kombination af det kartesiske produkt og en passende WHERE-betingelse, kan man også formulere det direkte i SQL: |
| Inner join i SQL |
SELECT ... FROM <tabel-1> JOIN <tabel-2> ON <betingelse> ...
|
|
Vores eksempel overfor bliver med denne notation: |
| |
SELECT * FROM person JOIN postnummer ON person.post_nummer = postnummer.nr
|
|
Resultatet bliver det samme. |
|
Som "..." antyder ovenfor, kan man supplere med en WHERE-betingelse, der begrænser hvilke af rækkerne fra inner join vi vil have med i udtrækket. |
|
Fordelen ved at anvende den specielle SQL-syntaks, er at serveren kan udføre operationen hurtigere. At lave et kartesisk produkt kan være meget krævende (hvis det er stort), og SQL serveren har normalt forskellige teknikker hvormed de kan undgå den store mellemregning. |
|
2.3 Delete |
|
Man kan slette en eller flere rækker med DELETE-sætningen: |
| |
DELETE FROM <tabel> WHERE <betingelse>
|
|
Vi kan f.eks. slette alle personer, der bor på Paradisæblevej: |
| |
DELETE FROM person WHERE gade = 'Paradisæblevej'
|
|
Der vil normalt altid være knyttet en WHERE-betingelse til DELETE-sætningen; hvis den udelades slettes alle rækker i tabellen! |
|
2.4 Update |
|
Man kan opdatere en eller flere rækker med UPDATE-sætningen: |
| |
UPDATE <tabel> SET <attribut-1>=<værdi-1>, <attribut-2>=<værdi-2> ... WHERE <betingelse>
|
|
Vi kan f.eks. flytte alle personer, der bor på Paradisæblevej til Bredgade 12: |
| |
UPDATE person SET gade='Bredgade', nr=12 WHERE gade = 'Paradisæblevej'
|
|
Der vil normalt altid være knyttet en WHERE-betingelse til UPDATE-sætningen; hvis den udelades vil alle rækker i tabellen få ændret de anførte attributter! |