| Heap betyder dynge |
Heaps (eng. heap: dynge, hob ) er binćre trćer, der er organiseret pĺ en anden mĺde end binćre sřgetrćer. Binćre sřgetrćer er kendetegnet ved den betingelse, der er knyttet til hver knude i trćet: At alle knuder i venstre undertræ er mindre end, og alle knuder i højre undertræ er střrre end, knuden selv. I heaps er der ogsĺ pĺlagt hver knude en ordningsbetingelse, den er dog simplere: | ||||||||
| |||||||||
|
I modsćtning til det binćre sřgetrćes vandrette ordning er heaps ordnet lodret langs enhver sti. | |||||||||
|
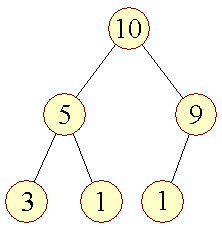
Lad os se et eksempel pĺ en heap: | |||||||||
| Figur 1: Et heap-trć |
| ||||||||
| Justere efterfřlgende |
I en heap skal vi naturligvis kunne indsćtte og udtage elementer. Alle operationer pĺ heaps udfřres ved at foretage ćndringen uden hensyntagen til heapbetingelsen og dernćst justere, sĺ ordningen bliver genoprettet. | ||||||||
|
| |||||||||
| Reprćsenteret som array |
Selv om man altid tćnker pĺ en heap som et trć, vćlger man ofte at reprćsentere dette trć som et array! Grunden er, at man kan gřre det pĺ en mĺde sĺ det er let at komme fra et břrn til en fader. Nĺr man arbejder med heaps har man nemlig brug for bĺde at arbejde oppefra/ned og nedefra/op. Det sidste er vanskeligt i en traditionel trć-reprćsentation. Man bemćrker, at array-reprćsentationen har en kedelig konsekvens: En trć-reprćsentation med pointere er dynamisk, mens et array er statisk. Det er dog en pris man er villig til at betale, da en array-reprćsentation ligeledes gřr det nemt at holde trćet komplet med deraf fřlgende logaritmisk hřjde. | ||||||||
|
Vi vil derfor realisere en heap som flg. container-klasse: | |||||||||
| Source 1: Container klassen |
| ||||||||
|
Hvor nodes[] er det array der indeholder knuderne og size er det aktuelle antal knuder i arrayet | |||||||||
| Level-order |
Vi vil lave array-reprćsentationen ved at liste knuderne som man lćser dem, fra venstre mod hřjre, og oppefra og ned, ogsĺ kaldet level-order. Eksemplet fra fřr, bliver derved: | ||||||||
| |||||||||
|
Hvis man betragter array-reprćsentationen observerer man den sammehćng, at en knude pĺ position i, har sine břrn pĺ position 2*i og 2*i+1. Og omvendt, at en knude har sin fader pĺ position i/2. Dette forudsćtter dog, at man regner den fřrste position (roden) som 1. Vi vil derfor set bort fra nodes[0], der ikke anvendes i det følgende. | |||||||||
|
| |||||||||
| Fra array uden ordning |
Vi vil nu studere en algoritme til konstruktion af en heap ud fra et array uden ordning. nodes[] vil altid kunne tolkes som en array-reprćsentation af et komplet trć, vi skal blot flytte rundt pĺ knuderne i array'et sĺ det bliver en heap. | ||||||||
|
Nĺr man skal konstruere denne array-reprćsentation gřres det vha. flg. rekursive metode [AHU 74, s. 90]: | |||||||||
| Pseudo 1: Heap-kontruktion |
| ||||||||
| Skov af heaps |
i og j fortćller metoden hvilket interval af nodes[], der allerede "er" en heap, nemlig ]i:j]. Metoden lřser problemet med at fřje i til, sĺ [i:j] "bliver" en heap. "er" og "bliver" er sat i anfřrselstegn, da det at en del af array'et betegnes som en heap, skal forstĺs pĺ den mĺde at alle knuder i del-array'et opfylder heapbetingelsen. Det betyder ikke at delarray'et ophřjet til array, med sine deraf følgende nye index, vil vćre en heap. Heapbetingelsen er kun opfyldt med index-positionerne fra hele array'et. Derfor břr man i stedet se pĺ den del af array'et, der "er" en heap, som en skov af trćer, der hver for sig er rigtige heaps. | ||||||||
|
Lad os se hvad der sker i trć-reprćsentationen | |||||||||
|
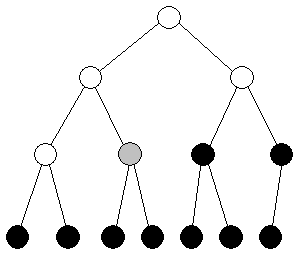
Situationen kunne pĺ et tidspunkt vćre flg.: | |||||||||
| Figur 2: Skov af heaps |
| ||||||||
|
De sorte knuder er den del ]i:j], der "er" en heap. Den grĺ knude er den i'te knude som vi nu vil fřje til. | |||||||||
|
Hvis den grĺ knude er střrre end begge sine břrn, opfylder den heap-betingelsen og kan den blot gřres sort. | |||||||||
|
Hvis en eller flere af břrnene er střrre, vil det střrste barn vćre det střrste af de tre. Vi kan derfor ved at swappe den grĺ knude med det střrste barn, skabe en situation, hvor heapbetingelsen er opfyldt, for den position i trćet den grĺ knude var pĺ. | |||||||||
| Boble ned |
Vi gentager nu denne proces, med at boble den grĺ knude ned igennem trćet, indtil den er střrre end begge sine břrn. | ||||||||
|
Da heapify bobler den nćste knude ned pĺ plads kunne man kalde den bobleDown, men vi vil forbeholde dette navn til den tilsvarende metode med kun én parameter, hvor j altid er size. | |||||||||
|
j kan bruges til at afgřre om i er et blad: Hvis i>j/2 sĺ er i et blad. Hvis i ikke var et blad, skulle den have břrn pĺ position 2*i og evt. 2*i+1, men da i>j/2 Ţ 2*i>j eksisterer disse positioner ikke (der er igen knuder sĺ langt henne i array'et). | |||||||||
|
At undersřge om $ k, hvor k er et barn til knuden pĺ position i, sĺ nodes[k]>nodes[i], altsĺ, at knude i ikke er střrre end begge sine břrn, gřres ved at se pĺ nodes[2*i] og nodes[2*i+1], med indledende check af, at den sidste eksisterer (den første vil altid eksisterer, da i ellers var et blad; hvilket vi startede med at udelukke). | |||||||||
|
heapify kan derfor implementeres ved: | |||||||||
| Source 2: Heap-kontruktion |
| ||||||||
| Ikke alene kalder heapify sig selv rekursivt, men den kaldes ogsĺ talrige gange af den overordnede metode: | |||||||||
| Source 3: Den overordnede metode |
| ||||||||
| Optimering | Man kan i stedet starte ved i=size/2. At dette er muligt kan man se ud fra et argumentet mht. antallet af blade i forhold til knuder i et komplet trć. Hver gang vi fjerner to blade i bunden, bliver der netop ét blad mere i nćst-nederste rćkke! Ergo vil halvdelen af alle knuder i et komplet trć vćre blade. | ||||||||
|
At algoritmen virker kan vises ved et baglćns induktionsbevis for: | |||||||||
| |||||||||
|
Man kan vise at tidskompleksiteten for arrayToHeap er O( n ) [AHU 74, s.90-91]. | |||||||||
| Arrayet delvist ordnet |
Pĺ grund af heapbetingelsen bliver array'et efter arrayToHeap delvist ordnet i aftagende orden. Der er altsĺ en vis grad af ordning, men skal vi have array'et helt sorteret mĺ vi overskride grćnsen mellem O(n) og O(n log n). Vi er derfor med arrayToHeap pĺ vej mod grćnsen mellem usorteret og sorteret fra den usorterede side. | ||||||||
|
Efter vi nu har en heap pĺ den řnskede array-form, vil vi se pĺ de metoder vi řnsker i en sĺdan container-klasse. | |||||||||
|
| |||||||||
| Nćste ledige plads |
insert laves ved at placere det nye element pĺ den nćste ledige plads i array'et: nodes[size+1], og dernćst justere sĺ heapbetingelsen igen er opfyldt. Det svarer i trćet til, at det nye element placeres pĺ den nćste ledige plads i bunden af trćet fra venstre mod hřjre, og dernćst bobler op indtil heapbetingelsen igen er opfyldt [Sedgewick 92, s.150]. | ||||||||
|
Vi fĺr derfor: | |||||||||
| Source 4: Overordnet indsćttelses-metode |
| ||||||||
|
hvor bobleUp laves ved: | |||||||||
| Source 5: Boble op |
| ||||||||
|
k>1 betyder, at A[k] ikke er roden. k/2 er som bekendt faderen til k. | |||||||||
|
Da vi konstruerede heapen med arrayToHeap, brugte vi heapify. Man fřjede et nyt element til fra oven og lod det boble ned til heapbetingelsen var opfyldt. heapify var lavet rekursiv og bobleUp kan naturligvis ogsĺ laves rekursiv. | |||||||||
| Source 6: Rekursiv bobleUp |
| ||||||||
|
Den iterative udgave af bobleUp tager elementet ud i v og foretager derefter kun halve swaps, for fřrst til sidst at fuldende "swappet". Den iterative vil derfor reelt vćre hurtigere, men de vil stadig have samme tidskompleksitet. | |||||||||
|
| |||||||||
|
Til at lave remove skal vi bruge bobleDown [Sedgewick 92, s. 152]: | |||||||||
| Source 7: Boble ned |
| ||||||||
|
k<=Size/2 betyder: "k er ikke et blad". Da det altid er den střrste af břrnene, der swappes med, bliver heapbetingelsen opretholdt i forhold til det andet barn. | |||||||||
|
Man laver remove ved at flytte nodes[Size] op på den tomme plads, der opstår efter roden er fjernet, og den bobles dernæst nedad i heapen: | |||||||||
| Source 8: Overordnet remove-metode |
| ||||||||
| O( log n ) |
bobleUp og bobleDown bruger hver O(log n), da de forlřber langs en sti i heap-trćet. Derfor bruger insert og remove ogsĺ O(log n). | ||||||||
|
2. Reprćsenteret som tripel-linket trć | |||||||||
| [Mangler - mĺ vente til en senere lejlighed] | |||||||||
|
| |||||||||
|
Nĺr vi udtager et element fra heapen er det altid det střrste, og man kan dermed bruge en heap til at sortere en rćkke elementer. | |||||||||
| Dobbelt sĺ lang tid som quisksort |
Ved denne metode kan man opnĺ O(n log n), men heapsort vil gennemsnitlig tage dobbelt sĺ lang tid som quicksort [Sedgewick 92, s.154]. | ||||||||
| O( n log n ) |
Da udgangspunktet for sortering altid er det samme: elementer i en tilfćldig rćkkefřlge, bruger vi naturligvis fřrst arrayToHeap, der tager O(n). Dernćst bruges remove n gange, altsĺ O(n log n), eftersom remove tager O(log n). Alt i alt O(n log n) for hele sorteringen. | ||||||||
| Sortering i samme array |
Da vi gerne vil have, at sorteringen, om muligt kan foregĺ i ét og samme array, flytter vi det udtagne element ned pĺ den ledige plads, som opstĺr i array'et efter det er justeret. Pĺ den mĺde kommer det střrste element, som vi fřrst udtager, ned pĺ sidste position osv.; hvorved elementerne bliver sorteret i ikke aftagende orden; hvilket generelt er vores mĺl ved sortering. | ||||||||
|
Vi kan samle sorteringen i en metode [AHU 74, s.91]: | |||||||||
| Source 9: Heap-sort |
| ||||||||
|
Vi ser nu behovet for to forskellige metoder, der foretager en boble ned, da vi her ćndrer endepunktet. | |||||||||
|
for-lřkken er en modificeret remove, til vores řnske om placeringen af det udtagne element. | |||||||||
|
| |||||||||
|
En traditionel kř behandler alle elementer lige. Elementer kommer ud i samme rćkkefřlge som de kommer ind, og ingen kan mase sig foran i křen. | |||||||||
|
I visse situationer kan man have behov for en struktur, der prioriterer de indkomne elementer, sĺ det element med hřjest prioritet i křen kommer fřrst ud. | |||||||||
| Prioritere behandling af kvćstelser |
Man kunne f.eks. forestille sig en prioritetskř anvendt i forbindelse med patienter pĺ en skadestue, hvor alvorlige kvćstelser bliver behandlet fřr mindre alvorlige. | ||||||||
|
Man skal bemćrke, at vi kun stiller det ene krav til prioritetskřer: at elementet med střrst prioritet er det nćste vi tager ud. Hvordan prioritetskřen ellers er implementeret er uden betydning for os. | |||||||||
|
Det betyder, at en heap er som skabt til en prioritetskř, idet vi fra den altid udtager det střrste element; hvor střrst i denne sammenhćng kunne vćre prioriteten. | |||||||||
|
Prioriteskřer har mange anvendelsesmuligheder. Man kan endog lave en traditionel kř, vha. en prioritetskř ved at lade elementernes vćrdi vćre -t; hvor t er et udtryk for ankomsttidspunktet. | |||||||||
|
Repetitionsspřrgsmĺl | |||||||||
| 1 | Hvad betyder heap? | ||||||||
| 2 | Hvad er heap-betingelsen? | ||||||||
| 3 | Hvorfor reprćsenterer man ofte et heap-trć i et array? | ||||||||
| 4 | Hvad er ulempen ved at bruge et array? | ||||||||
| 5 | Hvilken ordning svarer rćkkefřlgen knuderne fĺr i arrayet til mht. til trćet? | ||||||||
| 6 | Hvis en knude befinder sig pĺ position i; hvor er sĺ dens břrn og fader? | ||||||||
| 7 | Forklar hvordan der menes med en skov af heaps. | ||||||||
| 8 | Hvad sker der nĺr man bobler ned? | ||||||||
| 9 | Hvorfor kan man optimere heapify til at starte med i = size/2? | ||||||||
| 10 | Hvorfor bliver arrayet delvist ordnet efter heapify? | ||||||||
| 11 | Hvad sker der nĺr man bobler op? | ||||||||
| 12 | Er det den iterative eller den rekursive udgave af bobleUp, som er hurtigst? Forklar. | ||||||||
| 13 | Hvad er tidskompleksiteten for insert og remove? Forklar. | ||||||||
| 14 | Hvordan kan man bruge en heap til at sortere? | ||||||||
| 15 | Hvorfor er en heap god til at implementere prioritetskřer? | ||||||||
|
Projekter | |||||||||
| 1 | Lav en array-reprćsentation af et trć; hvor hver knude kan have hřjest n břrn, hvor bĺde n og det maximale antal niveauer fastlćgges ved instantieringen. | ||||||||
|
Svar pĺ repetitionsspřrgsmĺl | |||||||||
| 1 | hob eller dynge | ||||||||
| 2 | At der for enhver knude gćlder at begge břrn er mindre end eller lig med knuden selv | ||||||||
| 3 | Det bliver nemt at gĺ fra barn til fader, samt at trćet relativ enkelt holdes komplet, med deraf fřlgende logaritmiske tidskompleksitet | ||||||||
| 4 | Et array er statisk. Det skal derfor pĺ forhĺnd vćre fastlagt hvor mange knuder der maximalt kan vćre i heap-trćet | ||||||||
| 5 | Level-order | ||||||||
| 6 | Det ene barn pĺ position 2*i, det andet pĺ position 2*i+1 og faderen pĺ position i/2 | ||||||||
| 7 | Det er en samling af trćer der hver for sig er heap-trćer. I heapify arbejder man med en sĺdan skov af heaps; hvor man dog skal bruge de index der stammer fra det sammede array. | ||||||||
| 8 | Sĺ swapper man knuden med det střrste af břrnene. Dette fortsćtter man med indtil knuden er střrre end begge břrnene. | ||||||||
| 9 | Det skyldes at halvdelen af alle knuder i et komplet trć er blade. | ||||||||
| 10 | Fordi en heap er ordnet langs alle stier fra rod til blad, og at břrnene til et barn altid har et střrre index end knuden selv | ||||||||
| 11 | Man swapper knuden med faderen. Dette gřres indtil faderen er střrre end knuden selv | ||||||||
| 12 | Den iterative er hurtigst, fordi den kan nřjes med "halve" swaps | ||||||||
| 13 | Den er O( log n ), fordi de begge forlřber langs en sti i trćet. Da trćet er komplet fřlger det at hřjden er logaritmisk. | ||||||||
| 14 | Man smider alle data ind i heapen (heapify fra et array vil vćre bedst); hvorefter man udtager alle elementerne. Disse vil komme i ikke stigende orden, hvorved de bliver sorteret | ||||||||
| 15 |
Fordi man kan betragte knudernes vćrdi som deres prioritet. Hřj vćrdi lig hřj prioritet |