|
Set i historiens lys spiller filer en stadig mindre rolle i forbindelse med udviklingen af almindelige applikationer. Grunden til dette er den stadig lettere adgang til databaser. Filers rolle er at repræsentere persistente data, og som sådan er de i konkurrence med databaser, der tilbyder mere end blot en flad file-struktur, og selv håndterer de filer der skal indeholde data. Mens databaser understøtter en struktur, i form af tabeller, records og typer, skal vi med filer selv implementere noget sådant. Mange databaseværktøjer tilbyder også automatisk rapport-generering, og det kan være bekvemt at gøre sådanne rapporter til en del af systemets output. |
|
1. Sekventielle filer |
| Sekventielle filer er relativ primitive |
I en sekventiel file ligger data i en lang række, hvor man læser henholdsvis skriver i en uafbrudt strøm. Man kan derfor ikke "rette" i en sekventiel file. Til det formål har man random access filer som vi skal se senere. Sekventielle filers life-cycle starter med én skrivning hvor alle data placeres i filen, efterfulgt af et vilkårligt antal læsninger, hvor man læser fra starten og fremad. Det er dog muligt senere at skrive i filen igen, men kun i fortsættelse af slutningen af filen (kaldet eof: end of file), som om man stadig var ved at skrive i den, men blot havde holdt en pause — i.e. det er ikke muligt at overskrive data, der allerede befinder sig i en sekventiel file. |
|
Lad os se et eksempel. |
|
Vi skriver først tallene fra 0 til 9 i en file. Vi kan illustrere dens udseende med følgende: |
Figur 1:
File med ti tal og eof |
 |
|
eof er placeret som et sidste virtuelt element, der indikerer hvor filen slutter. |
|
Vi kan nu læse data fra denne file gentagne gange, men hver gang vi starter må vi begynde forfra. Det er ikke muligt at bevæge sig baglæns i en sekventiel file - mærker understøttes nemlig ikke (vedrørende betydningen og anvendelsen af mærker, se evt. kapitlet "Streams"). |
|
Hvis vi senere skulle få brug for at føje flere data til filen, kan det kun gøres for enden - altså fra eof. |
Figur 2:
File efter tilføjelse af fem tal |
 |
|
her har vi fortsat med fem tal mere. |
| bytes eller chars |
Der findes to forskellige slags klasser i java.io der bruges til at arbejde med sekventielle filer. Den første gruppe består af FileInputStream og FileOutputStream. Disse klasser bruges når data er bytes, dvs. lowlevel data. Den anden gruppe er FileReader og FileWriter, der bruges når man vil arbejde med tegn (chars). Vi vil se på disse to grupper af klasser i det følgende. |
|
1.1 FileInputStream og FileOutputStream |
|
1.1.1 Åbning og lukning af filer |
|
Man får adgang til data i en file ved at åbne den. Det sker ved anvendelse af konstruktoren for henholdsvis FileInputStream og FileOutputStream. Vi har her de tre konstruktorer for FileInputStream: |
|
FileInputStream( String name )
FileInputStream( FileDescriptor fd )
FileInputStream( File file ) |
|
De findes fuldstændig tilsvarende for FileOutputStream. |
| Filenavn |
Den første af dem tager et filenavn som parameter. Dette filenavn er platformafhængigt og kan være enten et simpelt filenavn, med relativ sti eller absolut sti. Hvis man ikke angiver nogen sti er default directory det sted programmets class-filer ligger. En relativ sti vil også tage udgangspunkt i dette directory. |
|
Afvikler man sine programmer under Windows, kan man som filenavn også anvendes et såkaldt Win32 UNC navn. Et eksempel på et sådan UNC navn er: |
|
|
|
Der angiver filen test.txt, der befinder sig på maskinen ved navn Flame i det directory der er shared med navnet public. |
|
Det gælder generelt i Java, at man kan bruge UNC navne. |
| Tip! |
I forbindelse med stier er det forskelligt hvilken vej skråstregen skal vende, alt efter om man arbejder med UNIX '/', eller Windows '\'. Java er ligeglad med hvilken man bruger, uanset hvilken platform man arbejder på, vil den virtuelle maskine selv finde ud af hvad der skal bruges og transparent foretage en evt. oversættelse. Som bekendt bruges '\' som escape-karakter i tekstliteraler, og den fortolkes derfor ikke som et almindelig tegn. Ønsker man at bruge tegnet '\' i et tekstliterale, skal man skrive "\\"; hvilket man ofte vil glemme. Det er en træls fejl, og man bør derfor altid bruge '/' og overlade resten til den virtuelle maskine. |
|
Den anden konstruktor tager en FileDescriptor som parameter. En FileDescriptor er et handle, der kan bruges som kastebold mellem klienter. FileDescriptor har beskedne to metoder: |
|
void sync()
boolean valid() |
|
sync bruges hvis man vil sikre sig mod, at der ligger data i buffere som endnu ikke er blevet skrevet fysisk ud i filen. Det kan have betydning hvis f.eks. strømsvigt er et reelt problem. |
|
valid checker om FileDescriptor pt. repræsenterer en eksisterende åben file. |
|
Man skal aldrig selv lave instanser af FileDescriptor. Såfremt man alligevel gør det vil de være invalid. |
|
Både FileInputStream og FileOutputStream har en metode: |
|
|
|
der kan anvendes hvis man ønsker at få en FileDescriptor til den bagvedliggende file. |
|
Den tredie konstruktor for FileInputStream og FileOutputStream tager en File som parameter. Vi skal senere se på de mange muligheder et File-objekt giver og vil derfor forbigå det her, og blot bemærke at en File er et slags handle. |
|
FileOutputStream har en 4. konstruktor: |
|
FileOutputStream( String name, boolean append ) |
| Tilføje data |
Den giver mulighed for at tilføje (eng.: append) data til en allerede eksisterende sekventiel file. Hvis man angiver true vil data, der skrives til filen, blive tilføjet fra eof, mens man med false vil slette og åbne filen på samme måde som konstruktoren uden denne ekstra parameter. |
|
For alle filer gælder der, at man skal være omhyggelig med at lukke dem efter brug. Dette gøres med metoden: |
|
|
|
Det er i særdeleshed vigtigt fordi en file der er åbnet til skrivning ikke kan læses og visa versa. Hvis man glemmer at lukke filer, risikerer man derfor at blokkere en anvendelse andre steder i programmet. |
|
Når et program terminerer, lukkes alle filer automatisk, men man kan ikke være sikker på at eventuelle buffere tømmes. Derfor bør man designe sine programmer så de altid lukker filer selv. |
|
1.1.2 Læsning og skrivning |
|
Indlæsning med FileInputStream foregår vha. en af følgende tre metoder: |
|
int read()
int read( byte[] b )
int read( byte[] b, int off, int len ) |
|
Den første udgave af read indlæser en byte og returnerer den som en int. Med byte menes der ikke en værdi tilhørende værdimængden for Java's primitive type byte, men en værdi tilhørende [0:255]. read returnerer -1 hvis eof er nået (dvs. hvis man forsøger at indlæse eof). |
|
De to næste udgaver af read indlæser bytes i en buffer der gives med som parameter. De returnerer antallet af bytes der blev indlæst i bufferen, eller -1 hvis den første byte der blev forsøgt læst, var eof (dvs. ingen bytes blev indlæst). Den sidste af de to metoder giver mulighed for at angive hvor i bufferen de indlæste bytes skal placeres (se evt. kapitlet "Streams" afsnit 1.1.1, vedrørende angivelser af delarrays med offset og længde). |
| Overspringe |
Hvis man under indlæsningen ønsker at overspringe et vist antal bytes kan man anvende metoden: |
|
|
|
Antallet af bytes man ønsker at overspringe gives med som parameter. Metoden returner det antal bytes det lykkedes at overspringe. |
|
Udskrivning med FileOutputStream foretages vha. en af følgende tre metoder |
|
void write( int b )
void write( byte[] b )
void write( byte[] b, int off, int len ) |
|
Den første udgave af write udskriver en byte, som gives med som parameter. |
|
De to andre udskriver fra en buffer af bytes der gives med som parameter (se ovenfor vedr. offset) |
| IOException |
Bemærk at samtlige metoder, der er nævnt i dette afsnit kan kaste en IOException. |
|
1.1.3 eof som sentinel-værdi |
|
Når man læser fra filer, typisk med sentinel-styret iteration, har man behov for at håndtere eof som sentinelværdi. Der er to muligheder. |
| Side-effekt |
FileInputStream blokkerer ikke, så man kan altid fortsætte med at læse med den parameterløse read, der vil returnere -1 når man når eof, og dermed slutningen af datakilden. Det er umiddelbart en enkelt måde at håndtere problematikken, men det leder nemt til udtryk med side-effekter, da man nu både skal læse, gemme og teste. F.eks.: |
Source 1:
Side-effekt |
int next;
while ( (next=f.read()) >= 0 ) {
...
}
|
|
som man ikke så sjældent ser. Problemet er naturligvis det samme som for alle andre side-effekter (her assignment), nemlig at læsbarheden nedsættes betydeligt. |
|
Man kan modificere det til: |
Source 2:
Indledende l?sning og redundans |
int next = f.read();
while ( next >= 0 ) {
...
next = f.read();
}
|
|
men kode-redundansen med to gange f.read er heller ikke for køn. |
|
Der er en helt anden mulighed, nemlig at anvende available, der returnerer antallet af bytes, som er tilbage i datakilden. |
Source 3:
available-metoden |
while ( f.available() > 0 ) {
int next = f.read();
...
}
|
|
Man kan naturligvis mene at det fylder lige så meget som eksemplet ovenfor med kode-redundans, men af de tre er det den letteste at læse — det boolske udtryk er klart formuleret! |
|
1.1.4 Eksempel |
|
Lad os til slut se et eksempel, der anvender FileInputStream og FileOutputStream: |
Source 4:
Anvendelse af FileInputStream og FileOutputStream |
Main.java
import java.io.*;
public class Main {
public static void main( String[] args ) {
String filename = "test.data";
try {
FileOutputStream output = new FileOutputStream( filename );
for ( byte b=0; b<10; b++ )
output.write( b );
output.close();
}
catch ( FileNotFoundException e ) {
System.out.println( "Filen kunne ikke oprettes: " + filename );
}
catch ( IOException e ) {
System.out.println( "Der opstod fejl under skrivning til: " + filename );
}
try {
FileInputStream input = new FileInputStream( filename );
while ( input.available() > 0 )
System.out.print( input.read() + " " );
System.out.println();
input.close();
}
catch ( FileNotFoundException e ) {
System.out.println( "Filen findes ikke: " + filename );
}
catch ( IOException e ) {
System.out.println( "Der opstod fejl under læsning fra: " + filename );
}
}
}
|
|
Programmet laver en file test.data og udskriver tallene fra 0 til 9 som bytes i den. Dernæst indlæser den tallene fra filen og udskriver dem. |
|
Bemærk FileNotFoundException, der kan kastes af konstruktorerne. |
|
1.2 FileReader og FileWriter |
|
Forskellen mellem FileReader og FileWriter og deres modstykker FileInputStream og FileOutputStream, ligger i, at der her arbejdes med chars, i modsætning til bytes. |
|
1.2.1 Åbning og lukning af filer |
|
I forbindelse med åbning af filer har FileReader og FileWriter de samme konstruktorer som deres modstykker FileInputStream og FileOutputStream. Disse konstruktorer fungerer ligeledes på samme måde, og der er derfor ikke noget nyt om åbning af filer. |
|
Det samme gør sig gældende for metoden close, som ligeledes er den samme. |
|
1.2.2 Læsning og skrivning |
|
Disse to funktioner er også meget lig dem vi kender fra FileInputStream og FileOutputStream. Forskellen ligger i, at der arbejdes med chars i stedet for bytes. |
|
read-metoderne er de samme, blot med chars. |
|
For write findes der også tilsvarende metoder med chars, men der er nogle ekstra i forhold til FileOutputStream. Det drejer sig om følgende metoder: |
|
void write( String s )
void write( String s, int off, int len ) |
|
De er analoge til de tilsvarende write-metoder med et char-array, idet de i stedet tager en String som parameter. |
| ready |
Metoden available, som er kendt fra FileInputStream, findes ikke i FileReader. I stedet har FileReader en metode ready, der boolsk returnerer hvad der for FileInputStream svarer til available() > 0, dvs. om der er mere at læse fra filen. |
|
1.2.3 Eksempel |
|
Lad os se et eksempel, der anvender FileWriter og FileReader: |
Source 5:
Anvendelse af FileReader og FileWriter |
Main.java
import java.io.*;
public class Main {
public static void main( String[] argv ) {
String filename = "test.txt";
try {
FileWriter output = new FileWriter( filename );
output.write( "Dette er" + "\n" );
output.write( "en Test" + "\n" );
output.write( "af FileWriter og" + "\n" );
output.write( "FileReader" + "\n" );
output.close();
}
catch ( FileNotFoundException e ) {
System.out.println( "Filen kunne ikke oprettes: " + filename );
}
catch ( IOException e ) {
System.out.println( "Der opstod fejl under skrivning til: " + filename );
}
try {
FileReader input = new FileReader( filename );
while ( input.ready() )
System.out.print( (char) input.read() );
input.close();
}
catch ( FileNotFoundException e ) {
System.out.println( "Filen findes ikke: " + filename );
}
catch ( IOException e ) {
System.out.println( "Der opstod fejl under l?sning fra: " + filename );
}
}
}
Dette er
en Test
af FileWriter og
FileReader
|
|
Programmet udskriver fire linier tekst til filen test.txt. Dernæst indlæses de igen med udskrift til skærmen. |
|
1.2.4 Eksempel med BufferedReader og BufferedWriter |
|
Normalt bruger man ikke direkte FileReader når man ønsker at indlæse tekst. Det skyldes at FileReader for de fleste anvendelser er for lowlevel. En indlæsning af enkelttegn er sjældent praktisk. |
|
I stedet supplerer man FileReader med en BufferedReader; hvilket giver mulighed for at anvende metoden readLine, der returnerer en hel linie tekst. |
|
Det er ligeledes også nyttigt at supplere FileWriter med en BufferedWriter, da denne har en metode newLine, der udskriver et linieskift. Det bemærkes i den forbindelse at linieskift på file-niveau er platformsafhængig, og det derfor er nyttigt at kalde en metode i stedet for selv at skulle angive linieskiftet som chars. |
|
Eksemplet ovenfor, vil med anvendelse af BufferedReader og BufferedWriter få følgende udformning: |
Source 6:
Anvendelse af BufferedReader og BufferedWriter |
Main.java
import java.io.*;
public class Main {
public static void main( String[] argv ) {
String filename = "test.txt";
try {
BufferedWriter output = new BufferedWriter( new FileWriter( filename ) );
output.write( "Dette er" );
output.newLine();
output.write( "en Test" );
output.newLine();
output.write( "af BufferedWriter og" );
output.newLine();
output.write( "BufferedReader" );
output.newLine();
output.close();
}
catch ( FileNotFoundException e ) {
System.out.println( "Filen kunne ikke oprettes: " + filename );
}
catch ( IOException e ) {
System.out.println(
"Der opstod fejl under skrivning til filen: " + filename );
}
try {
BufferedReader input = new BufferedReader( new FileReader( filename ) );
while ( input.ready() )
System.out.println( input.readLine() );
input.close();
}
catch ( FileNotFoundException e ) {
System.out.println( "Filen findes ikke: " + filename );
}
catch ( IOException e ) {
System.out.println(
"Der opstod fejl under l?sning fra filen: " + filename );
}
}
}
Dette er
en Test
af BufferedWriter og
BufferedReader
|
|
2. Random access filer |
| Vilkårlig tilgang til data |
Har man behov for at arbejde med filer, hvor man både ønsker at kunne skrive og læse i den samme file, kan man anvende random access filer. Betegnelsen "random access" finder vi også i RAM (Random Access Memory), og i begge tilfælde skal ordet "random" ikke forstås som "tilfælde", men som "vilkårlig". Man har mulighed for at tilgå et vilkårligt stykke data. Dette gør sig nemlig ikke gældende for sekventielle filer, hvor man kun kan håndtere det næste element - ikke et efter eget valg. |
| Bytes |
I foregående afsnit om sekventielle filer arbejdede vi først med data som bytes, og dernæst som tekst. I forbindelse med random access filer arbejder vi kun med filer som bytes. Man skal derfor være indstillet på at arbejde med filer på et typemæssigt meget lavt niveau, når man vælger en løsning med random access filer. |
| Primitive typer |
Når man arbejder med random access filer, bruger man ikke streams. Man anvender en instans af klassen RandomAccessFile, og benytter de metoder den stiller til rådighed. Disse metoder arbejder ikke alene med bytes, men giver også mulighed for at håndtere de primitive datatyper int, char, boolean osv. Selvom dette løfter os lidt fra det rene byte-niveau, skal vi f.eks. stadig selv håndtere størrelse af disse datatyper. Man kan i den forbindelse glæde sig over at de primitive typer er præcist defineret, også på dette punkt. |
| |
RandomAccessFile har to konstruktorer: |
|
RandomAccessFile( File file, String mode )
RandomAccessFile( String filename, String mode ) |
|
Her er file henholdsvis filename, de sædvanlige to måder at angive en file på. Parameteren mode er enten "r" eller "rw", alt efter om man ønsker at begrænse sig til kun læsning af filen, eller ønsker både at kunne læse og skrive. |
|
RandomAccessFile har en lang række read- og write-metoder, men inden vi skal se på dem, vil vi først berøre spørgsmålet om hvor man er i filen. Ligesom man med sekventielle filer har en pointer i filen, der fortæller hvor man er kommet til, har man også en sådan i random access filer. Forskellen er blot, at vi i forbindelse med random access filer frit kan flytte denne pointer. |
|
Når filen åbnes er pointeren placeret ved position 0. Med følgende to set/get-metoder kan man manipulere pointeren: |
|
void seek( long pos )
long getFilePointer() |
|
Med seek-metoden kan man placere pointeren på en hvilken som helst position. Bemærk at der anvendes long, idet positioner angives i bytes, og filer kan have et ganske betydeligt omfang - med long kan der håndteres filer op til 8 mill. TB, hvilket må antages at være fremtidssikret :-) |
| Udefinerede værdier |
Sætter man pointeren til en position der rækker ud over filens nuværende længde, som man kan finde med length-metoden, vil filen ikke automatisk blive forlænget med det nødvendige antal bytes. Først når der skrives på den pågældende position vil de mellemliggende bytes blive allokeret. Det skal i den forbindelse bemærkes at de ekstra bytes, der derved allokeres, ikke er veldefinerede - dvs. de kan have tilfælde værdier. Dette er værd at bemærke, da Java ellers anvender initialisering med 0-ækvivalente værdier i de fleste andre sammenhænge - f.eks. allokering af arrays og instansvariable. |
|
Ønsker man at forøge filens længde til en vis størrelse, kan man også anvende følgende metode: |
|
void setLength( long length ) |
|
Her vil de ekstra bytes ligeledes være udefinerede. Såfremt man angiver en ønsket længde, der er mindre end den nuværende, vil filen blive afkortet, og de resterende data vil gå tabt. |
|
Da man med seek-metoden ikke er sikret mod at bevæge sig ud over filens længde, findes der en anden metode hvormed man kan flytte sig et vist antal bytes: |
|
|
|
Som parameter angiver man hvor mange bytes man ønsker at flytte pointeren fremad, og metoden returnerer hvor man bytes der reelt er rykket frem [Man bemærker at metoden, af uvis hvilken årsag, kun tager en int som parameter] |
|
Sammenligner man den med seek, er der den forskel at man med seek-metoden angiver en absolut placering af pointeren, mens man med skipBytes flytter sig rundt relativt i forhold til den nuværende position. |
|
Inden vi går over til read/write-metoderne er der kun at bemærke, at RandomAccessFile også har en close-metode som man bør anvende for at undgå tab af data. |
|
2.1 read/write-metoder |
|
Der findes et utal af read/write-metoder. Langt de fleste af disse metoder er erklæret i interfacene DataInput og DataOutput, som RandomAccessFile implementerer (der henvises til afsnittene om disse to interfaces i kapitlet "Streams"). |
|
RandomAccessFile har kun tre metoder der ikke er erklæret i de to førnævnte interfaces: |
|
int read()
int read( byte[] b )
int read( byte[] b, int offset, int length ) |
|
Alle tre metoder indlæser bytes. |
|
Den første indlæser én byte og returnerer den som en int. Det er bekvemt at få byte'n som en int, da en byte i almindelighed regnes uden fortegn, mens den primitive type byte i Java regnes med fortegn. |
|
De to næste metoder indlæser bytes i et array af byte's. Når man arbejder med bytes i større stil er det mere rationelt at anvende Java's primitive type byte, selvom det kan gør livet lidt vanskeligere. Den første indlæser bytes fra index 0 og fremefter, indtil enten b er fuld, eller der ikke er flere bytes klar (ingen af read-metoderne kan blokkere). Begge metoder returnerer hvor mange bytes der reelt er indlæst i b. Den sidste metode gør det muligt at starte fra et andet index (offset) end 0, samt at begrænse til indlæsning i en del af array'et (length bytes frem fra offset). |
|
De tre tilsvarende write-metoder er underlig nok erklæret i DataOutput. Underligt, fordi de tre read-metoder ikke er erklæret i DataInput. Jeg har ikke kendskab til hvorfor der er denne manglende symmetri mellem de to interfaces. |
|
2.2 Eksempel: IntArray |
|
Vi vil i dette eksempel implementere en container-klasse, der skal repræsentere et array af integers. Motivationen er, at vi med en random access file vil kunne lave et array af umådelig stor længde (kun begrænset af operativsystemets begrænsninger) uden at belaste arbejdslageret. |
| Transparens |
Vi vil lave klassen så det bliver transparent for brugeren af klassen, hvor data rent faktisk befinder sig. Vores interface skal indeholde følgende metoder: |
|
void set( long index, int value )
get get( long index ) |
|
samt have en default-konstruktor. |
|
Lukning af filen vil vi i dette eksempel se bort fra, da det umuliggør den transparens vi ønsker. |
|
Datakerne og default-konstruktor bliver som følger: |
Source 7:
Datakerne og konstruktor |
(IntArray.java)
import java.io.*;
public class IntArray {
private RandomAccessFile file;
public IntArray() {
try {
file = new RandomAccessFile( "int_array.dat", "rw" );
} catch ( IOException e ) {
terminate();
}
}
|
|
Bemærk terminate-metoden vi kalder hvis der kastes en IOException. I almindelighed må sandsynligheden for at en sådan exception kastes regnes for umådelig ringe. Vi vil derfor opretholde transparensen ved selv at håndtere alle exceptions, ved at programmet terminerer med en fejlmeddelelse: |
Source 8:
terminate() |
(IntArray.java)
private int terminate() {
System.out.println( "IntArray: I/O Error" );
System.exit( 1 );
/* compileren vil ofte have en returnering
* hvor terminate() kaldes fra, derfor er det
* bekvemt at terminate() returnerer en dummy
* integer
*/
return 0;
}
|
|
bemærk at vi af bekvemmelighedsgrunde lader metoden returnere en dummy integer (dette vil aldrig ske da et kald af metoden altid vil terminere programmet) afht. get-metoden's catch: |
Source 9:
get(...) |
(IntArray.java)
public int get( long index ) {
try {
// flyt til det sted i filen der svarer til index
moveto( index );
return file.readInt();
} catch ( IOException e ) {
return terminate();
}
}
|
|
I get-metoden anvender vi en service-metode der placerer pointeren det ønskede sted i filen, og samtidig skriver ekstra 0-er i enden af filen, såfremt den ikke har den nødvendige længde: |
Source 10:
moveto(...) |
(IntArray.java)
private void moveto( long index ) throws IOException {
// gange med de fire bytes en int fylder
int fileIndex = 4 * index;
// checker om vi skal l?ngere ud end filens l?ngde
if ( file.length() < fileIndex ) {
// g?r til enden af filen
file.seek( file.length() );
// beregner hvor mange extra integers der skal v?re
long extra = index - file.length()/4 + 1;
// skriver det n?dvendige extra antal integers
for ( int i=0; i<extra; i++ )
file.writeInt( 0 );
}
file.seek( fileIndex );
}
|
|
Man bemærker her, at vi ganger index med 4, hvilket er en integers størrelse i bytes. If-sætningen placerer pointeren, og indsætter om nødvendigt de ekstra 0-er. |
|
moveto-metoden anvendes også i set-metoden: |
Source 11:
set(...) |
(IntArray.java)
public void set( long index, int value ) {
try {
// flyt til det sted i filen der svarer til index
moveto( index );
file.writeInt( value );
} catch ( IOException e ) {
terminate();
}
}
}
|
|
En simpel testanvendelse kunne være. |
Source 12:
Testanvendelse |
Main.java
public class Main {
public static void main( String[] argv ) {
IntArray array = new IntArray();
for ( int i=0; i<10; i++ )
array.set( i, i );
for ( int i=0; i<10; i++ )
System.out.println( array.get( i ) );
}
}
|
|
Filen: int_array.dat får følgende indhold: |
Figur 3:
int_array.dat |
 |
|
Man ser hvordan hver integer fylder 4 bytes. |
| Lukning af filen |
Vores løsning lukker som nævnt ikke filen, hvilket er en usikker løsning. Jeg mener at erindre, at alle filer efter sigende skulle lukkes af den virtuelle maskine, når programmet terminerer, men jeg har konkret observeret at den ikke altid gør det. Vil man derfor have en sikker løsning, må man give køb på transparensen, og lade brugeren eksplicit lukke filen, ved f.eks. at udstyre IntArray med en close-metode. |
|
2.3 Eksempel: klassen Person |
|
Vil man bruge random access filer til persistens af objekter, bliver det straks mere kompliceret. Drejede det sig om sekventielle filer kunne man anvende serialisering, men da man ikke kan vide sig sikker på hvor lang en byte-sekvens der fremkommer ved serialisering, og man endog ikke kan være sikker på at disse byte-sekvenser vil have den samme længde for forskellige instanser af den samme klasse, må vi ty til mere primitive midler. |
|
I overensstemmelse med vores sædvanlige princip: "Gør tingene der hvor de nødvendige data er til stede", vil vi lade instansen selv generere byte-sekvensen, og dette på en sådan måde at den altid har samme længde. |
|
Vores udgangspunkt er følgende simple klasse: |
Source 13:
grundlæggende class Person |
Person.java
public class Person {
private String navn;
private int alder;
private boolean køn;
public Person( String navn, int alder, boolean køn ) {
this.navn = navn;
this.alder = alder;
this.køn = køn;
}
}
|
|
Inden vi begynder at implementere en løsning, der kan gøre instanser af ovenstående klasse persistente i forbindelse med en random access file, vil vi indføre et interface, der er nyttigt i forbindelse med denne slags løsninger: |
Source 14:
interface FixedSizeSerializable |
FixedSizeSerializable.java
import java.io.*;
public interface FixedSizeSerializable {
public final static int BYTE_SIZE=1;
public final static int SHORT_SIZE=2;
public final static int INT_SIZE=4;
public final static int LONG_SIZE=8;
public final static int CHAR_SIZE=2;
public final static int BOOLEAN_SIZE=1;
public final static int FLOAT_SIZE=4;
public final static int DOUBLE_SIZE=8;
public boolean write( DataOutput file );
public boolean read( DataInput file );
}
|
|
I dette interface har vi defineret størrelsen af de forskellige primitive typer. Vi har også erklæret to metoder: read og write, der skal indlæse/udskrive instansens tilstand fra/til en RandomAccessFile. Vi valgt at bruge DataInput og DataOutput, da disse er mere generelle og RandomAccessFile implementerer disse interfaces. |
|
Lader vi nu Person realisere dette interface, vil vi kunne få instanser af Person til selv at serialisere sig, vel at mærke med en tilstands-uafhængig byte-længde. I den forbindelse er det kun variablen navn, der giver problemer. Den er en String, og dens længde er derfor ikke konstant. Vi vælger at begrænse navn's længde til 20 tegn: |
Source 15:
write(...) |
(Person.java)
private final static int NAVN_STR_SIZE=20;
public boolean write( DataOutput output ) {
try {
// navn (max. 20 tegn)
String navnStr = navn;
if ( navnStr.length() > NAVN_STR_SIZE )
navnStr = navnStr.substring( 0, NAVN_STR_SIZE );
else
while ( navnStr.length() < NAVN_STR_SIZE )
navnStr += " ";
output.writeChars( navnStr );
// alder
output.writeInt( alder );
// køn
output.writeBoolean( køn );
return true;
} catch ( IOException e ) {
return false;
}
}
|
|
Her har vi med rødt markeret konstanten NAVN_STR_SIZE og hjælpevariablen navnStr. Vi opbygger den ønskede tekststreng i navnStr ud fra navn. Den ønskede længde opnås ved enten at afkorte navnStr eller ved at tilføje det nødvendige antal mellemrum. |
|
Med blåt har vi markeret de metode-kald der udskriver. |
|
Ser man på read-metoden, er det igen håndtering af navn der fylder mest: |
Source 16:
read(...) |
(Person.java)
public boolean read( DataInput input ) {
try {
StringBuffer sb = new StringBuffer();
for ( int i=0; i<NAVN_STR_SIZE; i++ )
sb.append( input.readChar() );
this.navn = sb.toString().trim();
this.alder = input.readInt();
this.k?n = input.readBoolean();
return true;
} catch ( IOException e ) {
return false;
}
}
|
|
Vi indlæser 20 tegn og fjerne de evt. overflødige mellemrum med trim-metoden. |
|
Hvordan skal vi håndtere selve filen? read/write-metoderne i Person-klassen er afhængig af, at andre placerer pointeren, der hvor der skal skrives henholdsvis læses. Da det er Person-klassen, som ved hvor mange bytes den samlede serialisering fylder, kan man indføre en statisk konstant der oplyser om dette: |
Source 17:
BYTE_SIZE |
(Person.java)
public static final int BYTE_SIZE = NAVN_STR_SIZE * CHAR_SIZE + INT_SIZE + BOOLEAN_SIZE;
|
|
Konstanten bygger på Person-klassens egen konstant: NAVN_STR_SIZE, og de nedarvede konstanter fra interfacet: FixedSizeSerializable. |
|
Med en sådan konstant vil vi fra en testanvendelse kunne bevæge os rundt i en random access file, indeholdende serialiserede Person-objekter: |
Source 18:
Testanvendelse |
Main.java
import java.io.*;
public class Main {
public static void main( String[] argv ) {
try {
RandomAccessFile file = new RandomAccessFile( "personer.dat", "rw" );
Person[] personer = {
new Person( "Svend Svendsen", 25, true ),
new Person( "Jensine Jensen", 35, false ),
new Person( "Niels Nielsen", 45, true ),
};
for ( int i=0; i<personer.length; i++ )
personer[i].write( file );
file.seek( 1 * Person.BYTE_SIZE );
Person p = new Person();
p.read( file );
System.out.println( p );
file.close();
} catch ( IOException e ) {
System.out.println( "I/O Error" );
}
}
}
|
|
Idet vi implementerer følgende toString-metode i Person-klassen: |
Source 19:
toString() |
(Person.java)
public String toString() {
return "[Person: navn=" + navn + ", alder=" + alder + ", køn=" + køn + "]";
}
|
|
får vi følgende udskrift: |
|
[Person: navn=Jensine Jensen, alder=35, køn=false]
|
|
1-tallet vi ganger med i den røde linie i testanvendelsen (den med seek-kaldet), giver os pointerens placering for index 1 i random access filen. |
|
Lad os se filens indhold: |
Figur 4:
personer.dat |
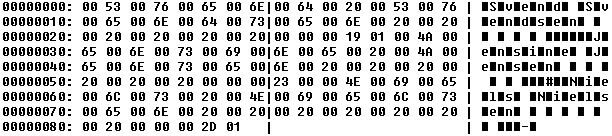 |
|
Man ser her at en char, som bekendt, fylder 2 bytes, og man kan også genkende mellemrummene (0x20). Ser man godt efter kan man ligeledes finde en integer og en boolean for hvert navn. Hver serialisering fylder 45 bytes - ialt 135 bytes for de tre instanser af Person. |
|
I testanvendelsen overfor placerer vi selv pointeren vha. konstanten. Denne opgave kunne overlades til selve Person-klassen: |
Source 20:
setPointer(...) |
(Person.java)
public static boolean setPointer( RandomAccessFile file, long index ) {
try {
file.seek( index * BYTE_SIZE );
return true;
} catch ( IOException e ) {
return false;
}
}
|
|
hvor testanvendelsen i stedet satte pointeren med: |
Source 21:
Ændring i testanvendelse |
(Main.java)
Person.setPointer( file, 1 );
Person p = new Person();
p.read( file );
|
|
Det bemærkes at konstanten BYTE_SIZE nu kan gøres private. |
|
Løsningen er mere i overensstemmelse med "Gør tingene hvor de nødvendige oplysninger er". Men der er to ulemper. |
| Komplicerer klassen |
For det første skal Person-klassen nu have kendskab til RandomAccessFile, og bliver dermed mere kompliceret/rodet. |
| Ikke i interfacet |
For det andet er det ikke muligt at pålægge alle der implementerer FixedSizeSerializable et krav om at de skal implementere setPointer, da et interface ikke kan indeholde en statisk metode-erklæring. At gøre setPointer til en instans-metode giver ringe mening, og vil være meget upraktisk at arbejde med. |
|
3. class File |
|
En instans af klassen File repræsenterer en file eller et directory. Den pågældende file eller directory behøver ikke eksistere! Der findes følgende metode til at fastslå den tilhørende file eller directory's eksistens: |
|
|
|
Og skulle man endog være i tvivl om der er tale om en file eller et directory kan man bruge følgende metoder: |
|
boolean isFile()
boolean isDirectory() |
|
Hvis filen eller directoriet ikke eksisterer, kan man lave det med en af følgende metoder: |
|
boolean createNewFile()
boolean mkdir()
boolean mkdirs() |
|
Forskellen på de to sidste metoder er at den første kræver at alle diretories på stien eksisterer, undtagen den sidste. Den anden laver selv de mellemliggende diretories på stien, som evt. ikke findes. Man kan derfor altid vælge at bruge den sidste. |
|
Før alt dette, skal man naturligvis først have en instans af File. Denne fås med en af følgende tre konstruktorer: |
|
File( String path )
File( String parent, String child )
File( File parent, String child ) |
|
Den første er langt den mest anvendte; hvor man direkte angiver stien til filen eller directory'et, som man normalt ville gøre det i andre sammenhænge man arbejder med filer eller directories. |
|
De to sidste gør det muligt at konstruere en ny File ud fra to delstier, der kombineres, men de er sjældent anvendt (jeg har endnu aldrig set nogen bruge dem!). |
|
De øvrige egenskaber ved filer og directories kan man checke med følgende metoder: |
|
boolean canRead()
boolean canWrite()
boolean isHidden()
String getName()
long lastModified()
long length() |
|
De to første fortæller os om de rettigheder vi har. Den tredie om filen eller directory'et er skjult (sjældent brugt). De tre sidste giver de oplysninger man typisk ser, når man lister et directory med filer og directories: navnet, størrelsen (af filer - directories er altid 0) og hvornår den sidste blev modificeret (for filer - directories er hvornår de blev lavet). |
|
LastModified kræver nok en kommentar. Den long der returneres er antallet af millisekunder siden midnat 1. januar 1970 (nytårsnat). Selve tallet er sjældent anvendeligt i sig selv, med mindre man blot ønsker at foretage en direkte før/efter sammenligning mellem to File-objekter. Tallet kan derimod bruges som parameter til konstruktoren til Date og på den måde være mere anvendeligt. |
|
Man kan ændre tre af ovenstående egenskaber med følgende metoder: |
|
boolean renameTo( File file )
boolean setLastModified( long time )
boolean setReadOnly() |
|
renameTo tager et File-objekt som parameter, der har det nye navn som man ønsker (det kan ikke bruges til at flytte filer eller diretories). |
|
Alle tre metoder returnerer boolsk om operationen lykkedes. |
|
Vil man slette en file eller et directory kan man bruge: |
|
|
|
Hvis man vil slette et directory skal det være tomt. |
|
3.1 Filtre |
|
Hvis File-objektet repræsenterer et directory kan man få en listning af indholdet med en af følgende tre metoder: |
|
File[] listFiles()
File[] listFiles( FileFilter filter )
File[] listFiles( FilenameFilter filter ) |
|
Disse metoder returnerer alle et array af File-objekter, der repræsenterer indholdet af directoriet. De to sidste metoder giver mulighed for kun at få listet visse af de filer og diretories som er i directoriet. De tager som parameter et filter der godkender eller forkaster de enkelte filer og directories. |
|
FileFilter og FilenameFilter er to interfaces, hvor den første retter sig mod både filer og directories, mens den sidste kun anvendes i forbindelse med filer. |
|
De to interfaces erklærer den samme metode: accept, men med forskellige parametre. |
|
For FileFilter er signaturen: |
|
boolean accept( File path ) |
|
og for FilenameFilter er den: |
|
boolean accept( File dir, String filename ) |
|
For den sidstes vedkommende er stien delt i to, idet filens navn anføres sammen med det directory hvori den befinder sig. |
|
3.2 Stier |
|
Stier kan være enten relative eller absolutte. En absolut sti tager udgangspunkt i roden, man kalder det også en fuld sti, fordi hele stien er angivet. En relativ sti kan ikke stå alene, den skal forstås i forhold til et directory - dette vil normalt være det directory hvorfra applikationen udføres. |
|
For en absolut sti er udgangspunktet som nævnt roden. I UNIX er der kun én rod, mens der i DOS er flere røder. For at holde Java platformsuafhængig, samtidig med at man gør det muligt at arbejde med de flere røder i DOS har man lavet følgende metode der returnere samtlige røder i filesystemet som et array af File-objekter: |
|
static File[] listRoots() |
|
Bemærk at metoden er static, da den ikke knytter sig til et bestemt File-objekt. |
|
Anvendelsen kunne f.eks. være følgende: |
Source 22:
Anvendelse af listRoots() |
Main.java
import java.io.*;
public class Main {
public static void main( String[] args ) {
File[] drives = File.listRoots();
for ( int i=0; i < drives.length; i++ )
System.out.println( drives[i] );
}
}
C:\
D:\
E:\
F:\
H:\
K:\
S:\
W:\
Z:\
|
|
Når man taler platformsafhængighed støder man også på spørgsmålet om '/' og '\'. UNIX anvender '/' og DOS bruger '\'. Java er ligeglad med hvilken man bruger, idet den regner dem for ækvivalente. Man bør derfor, som tidligere nævnt i dette kapitel, anvende '/', da man derved undgår problemer med '\', der som bekendt er givet ved tegn-literalet '\\'. |
|
Skulle det i en anvendelse være væsentligt, at man bruger de platformsafhængige tegn, har File fire konstanter der angiver disse: |
Source 23:
De to separators |
Main.java
import java.io.*;
public class Main {
public static void main( String[] args ) {
System.out.println( File.pathSeparator );
System.out.println( File.pathSeparatorChar );
System.out.println( File.separator );
System.out.println( File.separatorChar );
}
}
|
|
Ovenstående viser udskriften når programmet køres under Windows. |
|
Som man ser, er der i virkeligheden kun tale om to konstanter, idet de er repræsenteret både som chars og Strings (kan typemæssigt være bekvemt for den der anvender dem). |
|
Den første - pathSeparator - er operativsystemets måde at adskille flere på hinanden følgende stier. |
|
Den anden - separator - er operativsystemets måde at adskille directories i en stiangivelse. |
|
File har nogle metoder til at finde stien til den file eller det directory som File-objektet repræsenterer: |
|
String getPath()
File getAbsoluteFile()
String getAbsolutePath()
File getCanonicalFile()
String getCanonicalPath() |
|
Det er lettest at forstå funktionaliteten af disse metoder vha. et eksempel: |
Source 24:
Stien til et File-objekt |
Main.java
import java.io.*;
public class Main {
public static void main( String[] args ) {
File file = new File( "../test.txt" );
System.out.println( file.getName() );
System.out.println( file );
System.out.println( file.getPath() );
System.out.println( file.getAbsolutePath() );
System.out.println( file.getAbsoluteFile() );
System.out.println( file.getCanonicalPath() );
System.out.println( file.getCanonicalFile() );
}
}
test.txt
..\test.txt
..\test.txt
C:\Java\Projekter\Eksempel - File\..\test.txt
C:\Java\Projekter\Eksempel - File\..\test.txt
C:\Java\Projekter\test.txt
C:\Java\Projekter\test.txt
|
|
Ud over de nævnte metoder, har vi sneget et par ekstra linier ind, fordi de er værd at bemærke i denne sammenhæng. |
|
Først har vi udskrevet selve navnet: test.txt, så vi kan identificere det i de følgende linier. I forbindelse med instantieringen, har vi angivet at denne file befinder sig i parent directory: ... |
|
Man ser at getPath-metoden og toString-metoden giver det samme, nemlig den angivelse vi brugte til at instantiere File-objektet. |
| Absolut eller kanonisk sti |
De sidste fire metoder bruges til at få den fulde sti til et File-objekt, men de to sidste er mere intelligent end de to første. getAbsolute...-metoderne sætter blot current working directory sammen med den angivelse den finder i File-objektet, mens getCanonical...-metoderne parser den ved de to første metoder fremkomne sti, og foretager mulige forkortelser. I vores eksempel er den absolutte sti derfor lidt kluntet, med .. placeret inde i stien, mens den kanoniske sti har "regnet sig frem til" hvor det er. |
| String eller File |
Forskellen på de to get...Path-metoder og de tilsvarende get...File-metoder, er om der returneres en tekststreng eller et nyt File-objekt. get...File-metoderne returnerer et nyt File-objekt, der fås ved at angive, den ved den tilsvarende get...Path-metodes fundne sti, som parameter til File's konstruktor. I eksemplet ovenfor ser man da også, at toString-metoden på de to nye File-objekter, netop returnerer det samme som de to get...Path-metoder. |
|
|
|