|
|
1.
String
|
| Strings er immutable, dvs.
de kan ikke ændres
|
Det første ved Strings som man
måske bliver lidt overrasket over, er at de er immutable
(dk: uforanderlige, konstante), dvs. de kan ikke ændres
(se evt. Immutable pattern). Det er overraskende fordi vi altid
ønsker at arbejde med data, at ændre det.
StringBuffer, som vi senere skal se, understøtter denne
foranderlighed (eng.: mutability), men også ved at lave
nye tekstrenge kan man "ændre" dem; hvilket vi
også vil se i det følgende.
|
|
|
1.1 Instantiering
|
|
|
Man kan, med syntaktisk sukker,
instantiere en String ved direkte at anføre et
tekst-literale:
|
|
|
|
|
|
Men hvis man foretrækker en
notation der er syntaktisk konsistent med almindelig
instantiering, kan følgende bruges:
|
|
|
String s = new String( "Java" ); |
|
|
|
Dette er kun en af ni konstruktorer som
String stiller til rådighed. Vi vil tage dem i mindre
portioner:
|
|
|
String()
String( String s )
String( StringBuffer buffer ) |
|
|
|
Default-konstruktoren giver en tom
tekststreng.
|
| Interne repræsentation
er array af chars
|
Den anden brugte vi ovenfor og selvom
instantieringen så ud som traditionel instantiering er der
tale om en copy-konstruktor. Tekst-literalet vi anførte
gav faktisk også anledning til en instantiering, så
i virkeligheden er det dobbelt-arbejde. Der sker en kopiering af
den interne repræsentation, der er et array af chars.
|
| StringBuffer er mutable
modstykke til String
|
Den tredie konstruktor tager en
StringBuffer som vi skal se senere. På et vist
abstraktionsniveau er dette også en copy-konstruktor, da
den væsentligste forskel på String og StringBuffer
er at den første er immutable og den anden er mutable.
|
|
|
Lad os gå videre til den
næste gruppe af konstruktorer:
|
| Fra chars til
String
|
String( char[] text )
String( char[] text, int offset, int length ) |
|
|
|
Her kopieres tegn fra et array
henholdsvis et del-array af chars. Da den interne
repræsentation netop er et array af chars er der tale om
set-konstruktorer.
|
|
|
Den sidste gruppe af konstruktorer
tager udgangspunkt i et array af bytes:
|
| Fra bytes til
String
|
String( byte[] bytes )
String( byte[] bytes, int offset, int length )
String( byte[] bytes, String enc )
String( byte[] bytes, int offset, int length, String enc ) |
|
|
|
Den første og tredie konstruktor
konverterer fra et array, mens den anden og fjerde konverterer
fra et del-array til en String (Vedrørende betydningen af
offset og length, i forbindelse med angivelse af del-arrays, se
kapitlet "Streams og filer").
|
| Platform-afhængig
konvertering
|
Når der konverteres fra bytes til
chars, er det for de to første konstruktorers vedkommende
en platformafhængig konvertering, typisk noget
ASCII-lignende.
|
|
|
De to sidste anvender navngivne
konverteringer, der angives ved den sidste parameter.
[Jeg har ikke kunnet finde noget om
encodings]
|
|
|
Nok er String rig på
konstruktorer, men med hensyn til metoder er det
overvældende - hele 47 stk. bliver det til!
|
|
|
I det følgende er de opdelt i
grupper efter overordnet funktionalitet.
|
|
|
1.2 Sammenligninger
|
|
|
1.2.1 Lighed
|
|
|
Hvis man ønsker at teste for
lighed mellem to tekststrenge anvendes en af følgende to
metoder:
|
|
|
boolean equals( Object obj )
boolean equalsIgnoreCase( String s ) |
|
| Lighed kun muligt hvis
Object er String
|
Den første tager naturligvis
ikke en String men et Object som parameter, eftersom det er
naturligt at override Objects equals-metode når det drejer
sig om sammenligning. Man skal dog ikke lade sig vildlede - er
parameteren ikke en String vil den altid returnere false.
|
| Case-sensitiv eller
ej
|
equals implementerer case-sensitiv
sammenligning, dvs. bogstaverne skal ikke alene være
"de samme", de skal også have samme case
(store/små bogstaver). Hvis man ønsker en
ikke-case-sensitiv sammenligning opnås dette med den anden
metode equalsIgnoreCase.
|
|
|
1.2.2 Ulighed
|
|
|
Til leksikografisk sammenligning har
man metoderne:
|
|
|
int compareTo( Object obj )
int compareTo( String s )
int compareToIgnoreCase( String s ) |
|
|
|
Disse metoder er lidt af en rodebunke!
|
| To metoder til det
samme
|
Den første overrider Objects
compareTo-metode; hvilket er logisk nok. Hvis obj er en String
gør den det samme som den der tager en String som
parameter, ellers kaster den en ClassCastException, igen logisk
nok. Men hvad skal vi så med den der tager en String som
parameter? equals-metoderne har ikke denne dobbeltkonfekt med en
equals der tager en String som parameter! (at compareTo
overflødigt overloades er også udbredt i andre
klasser)
|
|
|
compareToIgnoreCase foretager
naturligvis en ikke-case-sensitiv sammenligning.
|
|
|
Hvad mener vi med leksikografisk
sammenligning og hvorfor returneres en int?
|
| Alfabetisk
sammenligning
|
Leksikografisk sammenligning kaldes
også alfabetisk sammenligning. Det drejer sig om ordningen
af ord: Hvilket ord kommer alfabetisk før et andet?
|
|
|
F.eks. "java" og
"cpp" (anden måde at skrive C++).
"cpp" kommer først, fordi 'c' kommer før
'j'. Man foretager ganske enkelt en sammenligning bogstav for
bogstav indtil de er forskellige, og den der kommer først
er den hvor det pågældende bogstav kommer
først i alfabetet. F.eks. "falump" og
"fabrik", hvor det først er det tredie tegn 'l'
og 'b' der er forskelligt, og da 'b' kommer før 'l' i
alfabetet kommer "fabrik" før
"falump".
|
|
|
Men hvad så med den
int-værdi der returneres?
|
| Sammenligning er
substraktion
|
Sammenligningen foregår i
realiteten som en substraktion, hvor den ene String
trækkes fra den anden. I eksemplet med "falump"
og "fabrik" vil resultatet blive:
|
|
|
String s1 = "falump";
String s2 = "fabrik";
int i = s1.compareTo( s2 );
System.out.println( i ); |
|
|
|
Men hvad er det for "tal" der
trækkes fra hinanden. chars er som bekendt i virkeligheden
integers, selv om vi normalt tænker på dem mere
abstrakt som tegn. Derfor giver 'l' - 'b' = 108 - 98 = 10
udemærket mening. Værdierne er UniCode
værdier.
|
| 'å' er placeret
uhensigtsmæssig i UniCode
|
Her støder vi som danskere
desværre på et problem! Da man lavede UniCode
tænkte man ikke på denne enkle og udbredte teknik,
til implementation af leksikografisk sammenligning, med at
trække tegn fra hinanden. Derfor er 'å' placeret
forkert i forhold til æ og ø.
|
| Kan lave korrekt
sammenligning med Collator
|
Hvis man derfor vil lave en korrekt
leksikografisk sammenligning indbefattende æ, ø og
å, må man anvende en Collator.
|
|
|
Som nævnt, compareTo-metoderne er
lidt rodede!
|
|
|
1.2.3 Start og slutning
|
|
|
Til at se om en tekststreng starter
eller slutter med en bestemt del-streng har String
følgende metoder:
|
|
|
boolean startsWith( String s )
boolean startsWith( String s, int offset )
boolean endsWith( String s ) |
|
| Kun
case-sensitive
|
De er alle case-sensitive og der findes
ikke ikke-case-sensitive versioner af dem.
|
|
|
F.eks.:
|
|
|
String s = "computer";
System.out.println( s.startsWith( "com" ) );
System.out.println( s.endsWith( "puter" ) );
System.out.println( s.startsWith( "Comp" ) );
System.out.println( s.endsWith( "brain" ) ); |
|
|
|
Den specielle udgave med et offset
burde måske ikke hedde startsWith, da den generelt
sammenligner den del af tekststrengen, der starter fra index
angivet ved offset, og har samme længde som parameteren,
med parameteren.
|
|
|
F.eks.:
|
|
|
String s = "science";
System.out.println( s.startsWith( "en", 3 ) );
System.out.println( s.startsWith( "cien", 2 ) ); |
|
|
|
1.2.4 Delsammenligninger
|
|
|
Ud over startsWith med offset har
String flg. metoder til sammenligning med del-strenge:
|
|
|
boolean regionMatches( int offset, String s,
int soffset, int len )
boolean regionMatches( boolean ignoreCase,
int offset, String s,
int soffset, int len ) |
|
| Også
ikke-case-sensitiv sammenligning
|
Forskellen på de to metoder er
den boolske parameter der angiver om det skal være en
ikke-case-sensitiv sammenligning eller ej.
|
|
|
offset er offset i tekststrengen selv,
mens s og soffset angiver den tekststreng der skal sammenlignes
med og offset i denne. Endelig angiver len hvor stor en del der
skal sammenlignes.
|
|
|
F.eks.:
|
|
|
String s1 = "procon";
String s2 = "confirm";
boolean b = s1.regionMatches( 3, s2, 0, 3 );
System.out.println( b ); |
|
|
|
1.3 Get-agtige metoder
|
|
|
Get-agtige metoder, er metoder der helt
eller delvist henter data fra tekststrenge, enten som String,
chars eller bytes.
|
|
|
1.3.1 String fra String
|
|
|
Til at få del-strenge af en
String har man følgende metoder:
|
|
|
String substring( int begin )
String substring( int begin, int end ) |
|
| Index-interval
|
Parameteren angiver det index-interval
der beskriver den del-streng man vil have en kopi af:
[begin:end[, altså inklusiv begin men eksklusiv end. Hvis
end udelades betyder det resten af tekststrengen fra og med
begin.
|
|
|
At det er eksklusiv end viser sig
nyttigt i flere sammenhænge, men under alle
omstændigheder er det blot et spørgsmål om at
korrigere med én, hvis man vil have det inklusiv.
|
|
|
F.eks.:
|
|
|
String s1 = "computer";
String s2 = s1.substring( 2, 4 );
System.out.println( s2 ); |
|
|
|
1.3.2 chars fra String
|
|
|
Et enkelt tegn får man med:
|
|
|
|
|
|
F.eks.:
|
|
|
String s = "string";
char c = s.charAt( 3 );
System.out.println( c ); |
|
|
|
hele tekststrengen som et array af
chars, fås med:
|
|
|
|
|
|
mens man kan få en del-streng som
et array af chars med:
|
|
|
void getChars( int begin, int end, char[] dst, int dstoffset ) |
|
|
|
Her kopieres chars fra tekststrengens
index-interval [begin:end[ over i arrayet dst fra index
dstoffset og frem.
|
|
|
1.3.3 bytes fra String
|
| Konvertering fra chars til
bytes
|
Mht. bytes er der, i modsætning
til chars, tale om en reel konvenrtering idet der ikke er en
direkte overensstemmelse mellem den indre repræsentation i
en String og bytes.
|
|
|
Der findes følgende metoder:
|
|
|
byte[] getBytes()
byte[] getBytes( String enc ) |
|
|
|
Den første konverterer
platformsafhængigt, typisk noget ASCII-lignende. Den anden
konverterer efter den encoding der angives som parameter.
[Jeg har ikke kunnet finde noget om
encodings]
|
|
|
1.4 Søge-metoder
|
| Første eller sidste
forekomst
|
Disse kan inddeles i to grupper. Dem
der søger den første forekomst og dem der
søger den sidste forekomst, af et tegn eller en
tekststreng.
|
|
|
1.4.1 Første forekomst
|
|
|
Følgende metoder finder den
første forekomst af et tegn eller en tekststreng:
|
|
|
int indexOf( int c )
int indexOf( String s ) |
|
|
|
Det der returneres er index svarende
til den første forekomst, for tekststrengens vedkommende,
index for det første af tegnene. Hvis tegnet henholdsvis
tekststrengen ikke findes, returneres -1.
|
|
| Hvis man ønsker at begynde
søgningen et stykke inde i tekststrengen findes der
følgende metoder
|
|
|
int indexOf( char c, int start )
int indexOf( String s, int start ) |
|
|
|
som begynder søgningen fra det
index der angives med index start.
|
|
|
1.4.2 Sidste forekomst
|
|
|
Svarende til de metoder der finder
første forekomst finder følgende metoder den
sidste forekomst:
|
|
|
int lastIndexOf( char c )
int lastIndexOf( String s ) |
|
|
|
Og tilsvarende
|
|
|
int lastIndexOf( char c, int start )
int lastIndexOf( String s, int start ) |
|
|
|
hvor der startes fra index start og
søges tilbage.
|
|
|
1.5 Metoder der "ændrer"
|
| Returnerer String hvor
ændring er udført
|
Da en String, som bekendt, er immutable
sker der ingen ændringer ved tekststrengen. Der returneres
i stedet en ny tekststreng hvor de pågældende
ændringer er udført i forhold til den oprindelige
tekststreng.
|
|
| Først er der:
|
|
|
String concat( String s ) |
|
|
|
Som navnet antyder, returneres en ny
teksstreng der opstå ved at concatenere
(sammensætte) tekststrengen med den der er angivet som
parameter.
|
|
|
F.eks.:
|
|
|
String s1 = "computer ";
String s2 = "science";
String s3 = s1.concat( s2 );
System.out.println( s3 ); |
|
|
|
Dernæst er der:
|
|
|
String replace( char oldChar, char newChar ) |
|
| Fjerner
whitespaces
|
Her returneres der en tekststreng, hvor
alle forekomster af tegnet oldChar er erstattet med newChar.
|
|
|
|
|
|
Returnerer tekststrengen, hvor alle
foranstående og efterstillede whitespaces er fjernet.
|
|
|
F.eks.:
|
|
|
String sender = "<john.doe@who.cares.com>";
sender = sender.replace( '<', ' ' );
sender = sender.replace( '>', ' ' );
sender = sender.trim();
System.out.println( sender ); |
|
|
|
I dette eksempel renser vi en
mail-adresse for de vinklede paranteser som en sådan
adresse nogen gange kan være indrammet af. Bemærk at
sourcen også virkede selv om sender oprindelig var uden
vinklede paranteser.
|
|
|
1.5.1 Case
|
| Store eller små
bogstaver
|
Det hænder at man gerne vil have
en tekststreng konverteret til ene store eller små
bogstaver. Det opnås med en af følgende metoder:
|
|
|
String toLowerCase()
String toUpperCase() |
|
|
|
Da der lokalt kan være specielle
bogstaver, som vi f.eks. har det på dansk med æ,
ø og å, kan man supplere ved at angive en Locale
ved en af flg. metoder:
|
|
|
String toLowerCase( Locale locale )
String toUpperCase( Locale locale ) |
|
| Ikke for æ, ø
og å
|
Man kan så glæde sig over
at æ, ø og å ikke er mere specielle end at
man ikke behøver anvende et Locale for de danske
bogstaver.
|
|
|
1.6 Static metoder
|
|
|
Klassen String har en række
static metoder ved navn valueOf, der er overloadede for en lang
række datatyper:
|
|
|
String valueOf( boolean b )String valueOf( char c )
String valueOf( char[] data )
String valueOf( char[] data, int offset, int length )
String valueOf( double d )
String valueOf( float f )
String valueOf( int i )
String valueOf( long l )
String valueOf( Object obj ) |
|
|
|
Funktionaliteten af dem, med de
primitive datatyper som parametre, ses af følgende
eksempel:
|
|
|
System.out.println( String.valueOf( true ) )
System.out.println( String.valueOf( 'g' ) )
System.out.println( String.valueOf( 3.8 ) )
System.out.println( String.valueOf( 5.3F ) )
System.out.println( String.valueOf( 6425 ) )
System.out.println( String.valueOf( 2343444123132L ) ) |
true
g
3.8
5.3
6423
2343444123132 |
|
| Konverterer til tekstuel
repræsentation
|
Der sker en konvertering fra datatype
til en almindelig tekstuel repræsentation svarende til
hvad man ville forvente at få ved blot at udskrive dem med
System.out.println. (PrintStream bruger i sine print-metoder
valueOf-metoderne, så sammenhængen går
egentlig den anden vej)
|
|
|
Versionen med et Object som parameter
gør det samme som hvis man havde kaldt toString på
det, blot med den forskel at hvis obj er null, returnerer
valueOf tekststrengen "null".
|
|
|
De to der tager et array henholdsvis et
del-array af chars, gør det samme som de tilsvarende
konstruktorer. Samtidig findes der to andre static metoder
copyValueOf, der overloaded med de samme parametre gør
nøjagtig det samme. Lidt overvældende med
tripel-repræsentation af denne funktionalitet, og jeg er
ikke bekendt med dens oprindelse.
|
|
|
1.7 Andre metoder
|
|
|
Der er nogle få andre metoder som
falder uden for kategori.
|
|
|
Den første er:
|
| Antal tegn
|
|
|
|
Den fortæller hvor mange tegn der
er i tekststrengen.
|
|
|
Dernæst er der den interessante:
|
|
|
|
|
|
Den berører problematikken med
at man ikke blot kan sammenligne tekststrenge for lighed med ==.
F.eks. får man følgende resultat, hvis man
intet-anende prøver:
|
|
|
String s1 = new String( "java" );
String s2 = new String( "java" );
if ( s1 == s2 )
System.out.println( "De er ens" );
else
System.out.println( "De er forskellige" ); |
|
|
|
Man kan så overveje hvorfor
følgende giver et andet resultat:
|
|
|
String s1 = "java";
String s2 = "java";
if ( s1 == s2 )
System.out.println( "De er ens" );
else
System.out.println( "De er forskellige" ); |
|
|
|
I det sidste eksempel bliver der kun
lavet en instans med indholdet "java", mens der i det
første bliver lavet to instanser, hver med indholdet
"java".
|
| Sammenligner
referencer
|
Det kan virke lidt rodet/forvirrende,
men det understreger at == sammenligner referencer og ikke det
tekstuelle indhold i String-objekter.
|
|
|
Men betragt nu følgende eksempel
med intern-metoden:
|
|
|
String s1 = new String( "java" );
String s2 = new String( "java" );
String i1 = s1.intern();
String i2 = s2.intern();
if ( i1 == i2 )
System.out.println( "De er ens" );
else
System.out.println( "De er forskellige" ); |
|
| Kanonisk
reference
|
De to String-referencer der returneres
fra de to forskellige instanser af String er ens. Man kalder det
en kanonisk reference, fordi det reference-mæssigt er en
fælles repræsentant for alle tekststrenge med det
tekstuelle indhold "java". En sådan unik
reference-repræsentant kan bruges til at lave en hurtigere
sammenligning end med equals.
|
|
|
2.
StringBuffer
|
| StringBuffer er
mutable
|
Det primære formål med
StringBuffer er at have en mutable tekststreng, dvs. en
tekststreng der kan ændre sig.
|
| Ledig plads i arrayet
gør det til en buffer
|
Det implementeres, ligesom String, vha.
et array af chars. Forskellen ligger i at dette normalt ikke er
udfyldt, men levner plads til at nye tegn kan indsættes og
andre editerende operationer. En sådan datastruktur med
ledig plads, der efterhånden fyldes op, kaldes en buffer.
Heraf navnet StringBuffer.
|
| Større buffer
reallokeres når den løber fuldt
|
På et tidspunkt kan bufferen
løbe fuld, hvis der indsættes tilstrækkelig
mange tegn i den. Hvis det sker, reallokeres det som et
større array med plads til flere tegn. At det reallokeres
vil sige at der allokeres et nyt og større array, og
indholdet af det gamle array kopieres over i det nye. Det er
naturligvis ikke specielt effektivt med store kopieringer, men
hvis det anvendes i behersket omfang er det ikke det store
problem.
|
| Buffer fordobles for hver
reallokering
|
For StringBuffer er den konkrete
reallokerings-strategi at lave et nyt array der er dobbelt
så stort som det gamle (Helt præcist dobbelt
så stort + 2). På den måde vil arrayet normalt
være mere end halv fyldt, samtidig med at det vokser
eksponentielt i størrelse. At det normalt er mindst halv
fyldt er rimelig økonomisk med pladsen. At
størrelsen vokser eksponentielt betyder at arrayets
reallokering over tid, ved konstant tilførsel af tegn,
vil ske med logaritmisk aftagende hyppighed, hvilket også
må betegnes som rimeligt.
|
|
|
StringBuffer har tre konstruktorer:
|
|
|
StringBuffer()
StringBuffer( int length )
StringBuffer( String s ) |
|
|
|
Default-konstruktoren laver et tomt
array med ene ledige pladser til tegn. Default-størrelsen
på dette array er 16 tegn.
|
|
|
Alternativt kan man anvende den anden
konstruktor, hvis man selv ønsker at bestemme
størrelsen på det tomme array.
|
|
|
Den sidste bruges hvis man initielt
ønsker at tildele arrayet et indhold. Ud over indholdet
allokeres yderligere plads til 16 tegn.
|
|
|
2.1 Indsættelse
|
|
|
De to store repræsentanter for
denne gruppe af metoder er append og insert. Store fordi de er
overloadede med en lang række datatyper som parametre.
|
|
|
Lad os først se på append:
|
|
|
StringBuffer append( boolean b )
StringBuffer append( char c )
StringBuffer append( char[] s )
StringBuffer append( char[] s, int offset, int length )
StringBuffer append( double d )
StringBuffer append( float f )
StringBuffer append( int i )
StringBuffer append( long l )
StringBuffer append( Object obj )
StringBuffer append( String s ) |
|
| append tilføjer
tekst
|
Som navnet append (dk.: tilføje)
siger, vil parameteren blive føjet til, efter den tekst
der allerede befinder sig i bufferen. For alle parametres
vedkommende gælder der, at det er
tekststrengs-repræsentationen der føjes til (se
evt. metoden valueOf i klassen String).
|
|
|
Lad os se et eksempel:
|
|
|
StringBuffer sb = new StringBuffer( "Dette" );
sb.append( ' ' );
sb.append( "er en test" );
sb.append( ' ' );
sb.append( 1 ).append( ' ' ).append( 2 );
sb.append( ' ' ).append( 3 );
System.out.println( sb ); |
|
| Kalde-sekvens
|
Det er også et eksempel på
princippet om, at hvis en metode ikke returnerer noget, så
kan den lige så godt returnere objektet selv, for så
kan det indgå i en kalde-sekvens som det er vist i de to
nederste linier af eksemplet.
|
|
|
Metoden insert er overloaded med de
samme datatyper som append, men har en parameter mere:
|
|
|
StringBuffer insert( int index, boolean b )
StringBuffer insert( int index, char c )
StringBuffer insert( int index, char[] s )
StringBuffer insert( int index, char[] s, int offset, int length )
StringBuffer insert( int index, double d )
StringBuffer insert( int index, float f )
StringBuffer insert( int index, int i )
StringBuffer insert( int index, long l )
StringBuffer insert( int index, Object obj )
StringBuffer insert( int index, String s ) |
|
| Der gøres plads til
det indsatte
|
Den ekstra parameter i forhold til
append, angiver hvor den tekstuelle repræsentation af den
anden parameter skal indsættes i bufferen.
Indsættelsen skal i den forbindelse forstås i
modsætning til overskrivning. De tegn der befinder sig i
bufferen fra index og fremefter flyttes så der
gøres plads til den tekst der skal indsættes.
|
|
|
Lad os se et eksempel:
|
|
|
StringBuffer sb = new StringBuffer( "tion" );
sb.insert( 0, "si" );
sb.insert( 2, "tua" );
System.out.println( sb ); |
|
|
|
2.2 Ændringer
|
|
|
Hvis man vil ændre teksten i
bufferen kan det gøres med
|
|
|
StringBuffer replace( int start, int end, String s ) |
|
|
|
Der erstatter tegnene i bufferen fra
index start (inklusiv) til index end (eksklusiv) med tegnene fra
teksstrengen s.
|
|
|
Lad os se et eksempel:
|
|
|
StringBuffer sb = new StringBuffer( "bilkøer" );
sb.replace( 3, 5, "auktion" );
System.out.println( sb ); |
|
| Der gøres plads til
det nye
|
Det der sker, er at tegnene i
del-arrayet angivet ved index-intervallet [3:5[ fjernes,
hvorefter "auktion" indsættes i dette
"mellemrum". Denne indsættelse er ikke
afhængig af at der er efterladt plads svarende til det der
skal indsættes, men laves analogt til funktionaliteten i
insert-metoden, hvor der laves den nødvendige plads ved
at flytte det resterende.
|
|
|
Man kan ændre et enkelt tegn med:
|
|
|
void setCharAt( int index, char c ) |
|
|
|
F.eks.:
|
|
|
StringBuffer sb = new StringBuffer( "start" );
sb.setCharAt( 2, 'o' );
System.out.println( sb ); |
|
|
|
Man sletter dele af tekststrengen med:
|
|
|
StringBuffer delete( int start, int end )
StringBuffer deleteCharAt( int index ) |
|
|
|
delete fjerner del-strengen svarende
til index-intervallet [start:end[.
|
|
|
F.eks.:
|
|
|
StringBuffer sb = new StringBuffer( "database" );
sb.delete( 2, 6 );
System.out.println( sb ); |
|
|
|
deleteCharAt fjerner det tegn der har
index.
|
|
|
En lidt speciel metode er
|
|
|
|
|
|
der spejlvender teksten.
|
|
|
F.eks.:
|
|
|
StringBuffer sb = new StringBuffer( "harmonika" );
sb.reverse();
System.out.println( sb ); |
|
|
|
2.3 Get-agtige metoder
|
|
|
StringBuffer har følgende
get-agtige metoder:
|
| De samme get-agtige metoder
som String
|
char charAt( int index )
void getChars( int begin, int end, char[] dst, int dstoffset )
String substring( int start )
String substring( int start, int end ) |
|
|
|
Disse fire metoder findes også i
klassen String og har nøjagtig samme funktionalitet.
|
|
|
2.4 Buffer-relaterede metoder
|
|
|
Først er der
|
|
|
|
|
|
som egentlig ikke er buffer-relateret,
idet den returnerer længden af den tekst der befinder sig
i bufferen, og ikke længden af bufferen selv.
|
|
|
Derimod er der
|
|
|
|
|
|
som giver selve bufferens længde.
|
|
|
Hvis man vil sikre sig at bufferen har
en vis minimum-størrelse gøres dette med
|
|
|
void ensureCapacity( int minimum ) |
|
|
|
der vil fordoble bufferlængden +
2, hvis det er tilstrækkeligt til at opnå den
ønskede minimums-kapasitet, ellers vil den direkte bruge
minimum som længden på den reallokerede buffer.
|
|
|
Der findes en anden metode
|
|
|
void setLength( int length ) |
|
|
|
der gør det samme som
ensureCapacity. Hvorfor der findes to metoder til dette er
uklart.
|
|
|
3.
StringCharacterIterator
|
| Er eneste
CharacterIterator
|
StringCharacterIterator er pt. den
eneste klasse der implementerer CharacterIterator interfacet. Ud
over metoderne i dette interface har StringCharacterIterator
ikke andre end dem den arver fra Object. Efter at have set
på konstruktorerne vil vi derfor koncentrere os om
metoderne i CharacterIterator interfacet (se evt. Iterator
pattern).
|
|
|
StringCharacterIterator har
følgende konstruktorer:
|
|
|
StringCharacterIterator( String s )
StringCharacterIterator( String s, int pos )
StringCharacterIterator( String s, int begin, int end, int pos ) |
|
|
|
Den første initialiserer
iteratoren med den angivne tekststreng og placerer cursoren
på position 0.
|
|
|
Den næste gør tilsvarende,
men placerer cursoren på position pos.
|
|
|
Den sidste initialiserer iteratoren
så den kan iterere over den angivne del-streng, der er
givet ved index-intervallet [begin:end[ i s. endelig placeres
cursoren på position pos.
|
|
|
3.1 CharacterIterator interfacet
|
|
|
Man bruger primært fem metoder
til at bevæge cursoren i den tekststreng der itereres
på.
|
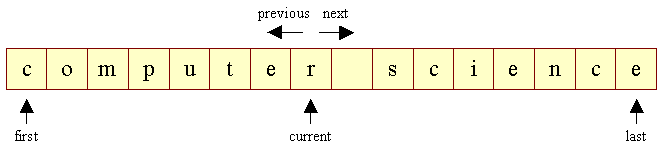
Figur 1:
De fem
iterator-metoder
|
|
|
|
Alle metoderne returnerer den char som
cursoren befinder sig ved efter
operationen er udført.
|
|
|
current returnerer den char som
cursoren peger på, uden at flytte den.
|
|
|
next flytter cursoren et tegn frem og
returnerer det tegn som cursoren derved kommer til at pege
på. previous fungerer analogt, idet den dog flytter
cursoren et tegn tilbage.
|
| Ud over
kanten
|
Hvis man prøver at flytte
cursoren ud over den tekststreng der itereres på,
returnerer next/previous værdien CharacterIterator.DONE
(der er 0xFFFF, som iflg. UniCode standarden er et invalid tegn,
og derfor kan bruges til sådanne formål).
|
|
|
first flytter cursoren til
første tegn og returnerer det tegn som cursoren derved
kommet til at pege på. last fungerer analogt idet den dog
flytter til det sidste tegn.
|
|
|
Mht. cursorens placering findes der to
konkrete set- og get-metoder:
|
|
|
char setIndex( int pos )
int getIndex() |
|
|
|
Ud over set-funktionaliteten returnerer
setIndex, i tråd med metoderne ovenfor, det tegn som
cursoren kommer til at pege på. Hvis pos ikke ligger inden
for de tilladte grænser for cursoren, kastes en
IllegalArgumentException.
|
|
|
CharacterIterator har endelig to
metoder
|
|
|
int getBeginIndex()
int getEndIndex() |
|
|
|
der returnerer starten og slutningen
på tekststrengens index-interval. Det skal som altid
forstås inklusiv/eksklusiv, dvs.
[getBeginIndex:getEndIndex[.
|
|
|
Lad os til slut se et eksempel med
StringCharacterIterator. Første del af eksemplet bruger
absolut cursor-styring og anden del anvender relativ
cursor-styring. Begge dele gennemløber tekststrengen og
udskriver elementerne med mellemrum.
|
Source 1:
Absolut og relativ
cursor-styring
|
import java.text.*;
class TestStringCharacterIterator {
public static void main( String[] argv ) {
StringCharacterIterator sci = new StringCharacterIterator( "computer_science" );
/*
* Absolut cursor-styring
*/
int begin = sci.getBeginIndex();
int end = sci.getEndIndex();
for ( int i=begin; i<end; i++ ) {
sci.setIndex( i );
System.out.print( sci.current() + " " );
}
System.out.println();
/*
* Relativ cursor-styring
*/
sci.first();
do {
System.out.print( sci.current() + " " );
} while ( sci.next() != CharacterIterator.DONE );
System.out.println();
}
} |
c o m p u t e r _ s c i e n c e
c o m p u t e r _ s c i e n c e |
|
|
|
I tekststrengen anvendes en underscore
i stedet for et mellemrum, for at tydeliggøre
"mellemrummet" i udskriften.
|
|
|
4.
StringTokenizer
|
| Opdele String i
tokens
|
Formålet med en tokenizer er at
opdele en sekventiel datastruktur i mindre dele, såkaldte
tokens. For StringTokenizer er det en tekststreng der skal skal
opdeles i mindre del-strenge, der ofte kan betegnes som ord,
specielle tegn og lignende.
|
|
|
Lad os starte med at se et eksempel,
for bedre at få et indtryk af en tokenizers
funktionalitet.
|
Source 2:
StringTokenizer
|
import java.util.*;
class TestStringTokenizer {
public static void main( String[] argv ) {
StringTokenizer st =
new StringTokenizer(
"En StringTokenizer kan nedbryde en tekststreng i tokens", " ", true );
System.out.println( "Der er i alt " + st.countTokens() + " tokens" );
while ( st.hasMoreTokens() )
System.out.print( "[" + st.nextToken() + "]" );
System.out.println();
}
} |
Der er i alt 15 tokens
[En][ ][StringTokenizer][ ][kan][ ][nedbryde][ ][en][ ][tekststreng][ ][i][ ][tokens] |
|
| Delimiters
|
Først laver vi en instans af
StringTokenizer. Som første parameter til konstruktoren
anfører vi den tekststreng vi vil tokenize. Dernæst
anføres som anden parameter de delimiters (dk.:
afgrænsere) som vi ønsker skal angive adskillelsen
mellem tokens som en tekststreng. Delimiters er altid
enkelt-tegn, og i vores tilfælde ønsker vi kun at
mellemrum skal være delimiter. Havde vi ønsket
flere delimiters havde vi blot anført dem som flere tegn
i tekststrengen til konstruktoren. Den tredie og sidste
parameter fortæller om vi ønsker at delimiters skal
optræde som tokens. Her vælger vi at de skal
gøre det for eksemplets skyld.
|
|
|
countTokens returnerer antallet af
tokens i tekststrengen, og man kan på den måde
få et overblik over hvor stor en historie man skal
igennem.
|
|
|
hasMoreTokens fortæller om der er
flere tokens tilbage i tekststrengen (true) eller om vi har set
den sidste (false). while-løkken kører så
længe der er flere tokens, og vi henter den med metoden
nextToken, der returnerer en tekststreng bestående af
næste token.
|
|
|
De tre metoder fra eksemplet
|
|
|
int countTokens()
boolean hasMoreTokens()
String nextToken() |
|
|
|
er de normalt anvendte.
|
|
|
Der findes reelt kun en metode mere:
|
|
|
String nextToken( String delimiters ) |
|
|
|
Denne overloadning af nextToken giver
mulighed for at angive en ny delimiter-streng, der vil erstatte
den gamle, også i følgende kald.
|
|
|
Valget mellem konstruktorerne
|
|
|
StringTokenizer( String s, String delimiters, boolean returnDelimiter )
StringTokenizer( String s, String delimiters )
StringTokenizer( String s ) |
|
| Default-værdier
|
er i forhold til den første, som
vi anvendte i eksemplet, blot et spørgsmål om vi
vil bruge default-værdierne eller selv anføre
andre. Default for returnDelimiter er false og default for
delimiters er "
\t\n\r\f", dvs. mellemrum, tabulering,
new-line, carriage-return og form-feed.
|
|
|
StringTokenizer har egentlig to metoder
mere. Det skyldes at StringTokenizer implementerer Enumeration
interfacet. Metoderne i dette interface gør det samme som
hasMoreTokens og den parameterløse nextToken, men med
Enumeration interfacet er det muligt for andre klasser i java,
som kan interaggere med dette interface, at arbejde med en
StringTokenizer.
|
|
|
4.1 Enumeration interfacet
|
|
|
Enumeration (dk.: opregning eller
opremsning) interfacet har beskedne to metoder:
|
|
|
boolean hasMoreElements()
Object nextElement() |
|
|
|
En Enumeration fungerer som en
engangs-iterator, der kun kan bevæge sig fremad og ikke
kan starte forfra.
|
|
|
Enumeration interfacet kom i JDK 1.0,
og det senere Iterator interface (se evt. Iterator pattern) i
JDK 1.2 anbefales frem for Enumeration - uden at man dog
betegner Enumeration interfacet som deprecated.
|
|
|
Lad os se et simpelt eksempel med
Enumeration interfacet.
|
Source 3:
Enumeration
interfacet
|
import java.util.*;
class TestEnumeration {
public static void main( String[] argv ) {
Enumeration enum = new StringTokenizer( "En enumeration er en simpel iterator" );
while ( enum.hasMoreElements() )
System.out.print( "[" + enum.nextElement() + "]" );
System.out.println();
}
} |
[En][enumeration][er][en][simpel][iterator] |
|
|
|
Repetitionsspørgsmål
|
|
| Spørgsmål om String:
|
| 1
|
Hvad vil det sige at String er
immutable?
|
| 2
|
Hvilken form for syntaktisk sukker kan
man anvende i forbindelse med instantiering af en String?
|
| 3
|
Hvad er den interne
repræsentation af en String?
|
| 4
|
Hvordan konverteres der mellem String
og et array af bytes?
|
| 5
|
Hvordan sammenligner man to String mht.
lighed?
|
| 6
|
Hvad er leksikografisk sammenligning?
|
| 7
|
Hvordan laver man leksikografisk
sammenligning af Strings?
|
| 8
|
Hvad er betydningen af den int som
compareTo-metoderne returnerer?
|
| 9
|
Hvilket dansk bogstav giver problemer
ved leksikografisk sammenligning og hvorfor?
|
| 10
|
Hvilke muligheder er der for at lave
sammenligninger af del-strenge?
|
| 11
|
Hvordan kan man få en del-streng?
|
| 12
|
Hvordan kan man søge i en
tekststreng?
|
| 13
|
Hvad vil det sige at man
"ændrer" en String?
|
| 14
|
Hvad gør metoden trim?
|
| 15
|
Hvad betyder "case" i
forbindelse med tekststrenge?
|
| 16
|
Hvad gør den statik metode
valueOf?
|
| 17
|
Hvorfor kan man ikke bruge == til at
sammenligne tekststrenge?
|
| 18
|
Hvad gør metoden intern?
|
|
| Spørgsmål om StringBuffer:
|
| 19
|
Hvad vil det sige at StringBuffer er
mutable?
|
| 20
|
Hvordan adskiller den interne
repræsentation i en Stringbuffer sig fra String?
|
| 21
|
Hvad er StringBuffers
reallokerings-strategi?
|
| 22
|
Hvad gør metoden append?
|
| 23
|
insert har en parameter mere end
append. Hvad angiver den?
|
| 24
|
Forklar hvordan replace fungerer?
|
| 25
|
Hvad gør reverse-metoden?
|
|
| Spørgsmål om StringCharacterIterator:
|
| 26
|
Hvad itererer en
StringCharacterIterator?
|
| 27
|
Hvad er det for en char alle
iterator-metoderne returnerer?
|
| 28
|
Hvad sker der hvis man forsøger
at iterere ud over kanten?
|
|
| Spørgsmål om StringTokenizer:
|
| 29
|
Hvad itererer en StringTokenizer?
|
| 30
|
Hvad er et token?
|
| 31
|
Får en delimiter-parameter i et
kald til nextToken kun betydning for det kald det indgår
i?
|
| 32
|
Hvad er default-delimiters?
|
| 33
|
Bliver delimiters default returneret
som tokens?
|
| 34
|
Hvad beskriver et Enueration interface?
|
|
|
Opgaver
|
| 1
|
Lav et program der spejlvender
tekststrengen i en StringBuffer, uden anvendelse af
reverse-metoden.
|
|
|
Svar på
repetitionsspørgsmål
|
| 1
|
At den ikke kan ændres - at den
er konstant.
|
| 2
|
Man kan skrive tekststrengen direkte
som et tekst-literale.
|
| 3
|
Et array af chars.
|
| 4
|
Der sker en platformafhængig
konvertering. Alternativt kan man anvende en encoding.
|
| 5
|
Enten med equals eller
equalsIgnoreCase, alt efter om det skal være case-sensitiv
sammenligning eller ej.
|
| 6
|
Det er et andet ord for alfabetisk
sammenligning som man kender det fra den alfabetiske ordning i
ordbøger og leksika.
|
| 7
|
Man bruger compareTo-metoden. Hvis man
ikke vil have en case-sensitiv sammenligning bruges
compareToIgnoreCase
|
| 8
|
Det er differencen (med fortegn) mellem
de to første tegn der ikke er ens.
|
| 9
| å, fordi dette i UniCode kommer
før æ og ø.
|
| 10
|
Hvis man vil se om en String starter
eller slutter med en del-streng kan man bruge startsWith eller
endsWith. Ellers kan man bruge en af de to
regionMatches-metoder. regionMatches-metoderne kan foretage en
ikke-case-sensitiv sammenligning; hvilket startsWith og endsWith
ikke kan.
|
| 11
|
Med substring-metoderne.
|
| 12
|
Man kan bruge indexOf eller
lastIndexOf, alt efter om man vil finde den første eller
sidste forekomst af en del-streng.
|
| 13
|
At en metode ændrer en String vil
sige at den returnerer en ny instans hvor ændringen er
foretaget.
|
| 14
|
Den fjerner alle foranstående og
efterstillede whitespaces.
|
| 15
|
Om det er store eller små
bogstaver.
|
| 16
|
Den returnerer en tekstuel
repræsentatione for en række datatyper.
|
| 17
|
Fordi == kun sammenligner referencerne
- ikke indholdet.
|
| 18
|
Den returnerer en kanonisk reference,
der er den samme for alle tekststrenge der har samme tekstuelle
indhold.
|
| 19
|
At den kan ændre sig.
|
| 20
|
Ved at arrayet af chars har ledig
plads.
|
| 21
|
At fordoble bufferens længde
når den løber fuld.
|
| 22
|
Den tilføjer tekst til bufferen.
Teksten placeres efter den tekst der allerede befinder sig i
bufferen.
|
| 23
|
Den angiver hvor teksten skal
indsættes.
|
| 24
|
replace fjerne en del-streng fra
bufferen der angives med et index-interval. Dernæst laver
den plads til den nye tekst og indsætter den der hvor den
fjerne del-strengen.
|
| 25
|
Den spejlvender tekststrengen.
|
| 26
|
Den itererer tegn i en String.
|
| 27
|
Den char som cursoren står ved
efter metoden er udført.
|
| 28
|
Der returneres en
StringCharacterIterator.DONE.
|
| 29
|
Den itererer tokens i en String.
|
| 30
|
Del-strenge der er afgrænsede af
delimiters.
|
| 31
|
Nej, den ændrer også
delimiters til de anførte også for
efterfølgende kald.
|
| 32
|
Mellemrum, tabulering, new-line,
carriage-return og form-feed.
|
| 33
|
Nej.
|
| 34
|
En engangs-iterator.
|
|
| |