| "Rigtige mænd tager ikke backup, men de græder ofte". Dette ordsprog kunne lige så vel passe på test — hvis man ikke laver test, kommer man til at fortryde det — jeg har tit fortrudt! | |||||||
| Hvornår er man færdig? | Test er ikke kun noget man gør, når man er færdig med at udvikle et system, det er noget der er en integreret del af hele udviklingsprocessen. En berømt udtalelse der faldt under et review, og som er blevet en klassiker er: "Vi er færdig med systemet. I øjeblikket prøver vi at få det til at fungere". Det er naturligvis en helt forfejlet opfattelse af forholdet mellem test og produkt, der ligger bag en sådan udtalelse — systemet er ikke færdig før det fungerer! Det der ligger i ovenstående citat er: "Vi er færdig med at programmere, så nu er systemet færdig. Nu skal vi bare lige have det til at virke, men det bliver sikkert ikke noget problem, for som sagt er vi færdige med at programmere!". | ||||||
| Denne holdning til hvad det vil sige at være færdig, kan sikkert spores helt tilbage til begynderens oplevelse af at lave et program. Ofte har man hørt udtalelsen: "Det virker!", for dernæst at konstatere, at det betød: "Efter at have compileret og rettet gentagne gange, er jeg nu nået dertil, at der ikke er flere compileringsfejl". I virkeligheden starter den mest omfattende del af testen først efter programmet kan compileres, men mere om det senere. | |||||||
| Maksimere pålidelighed | Dijkstra har engang sagt, at "man med en test kun kan bekræfte at der er fejl, ikke at der ikke er nogen". Med en test søger vi at finde fejl, men finder vi ingen, ved vi ikke om der stadig er fejl i systemet. Det eneste vi har bevist, er at vores test ikke kunne finde nogen fejl! Af den grund er der dem der mener at test i virkeligheden er et paradoks. Man gør "noget" for at gøre et system fejlfrit, og man ved på forhånd, at det ikke vil lykkes! Det lyder nedslående, men som man siger: "Hvis du ikke har succes, så redefiner succes!". Målet med test bliver derfor ikke at gøre systemet fejlfrit, men at gøre det så pålideligt som muligt. Vi erstatter altså et absolut mål, med et relativt. Et system kan være mere eller mindre pålideligt, vi søger at maksimere pålideligheden. | ||||||
| Minimere konsekvensen af fejl | Det pessimistiske syn på test — at det alligevel ikke gør vores system fejlfrit — fortæller os noget vigtigt om de systemer vi laver: De bliver ikke fejlfri! Det lyder umiddelbart som en banalitet, hvilket det også er, men det er alligevel værd at bemærke, for det bliver i vid udstrækning ignoreret. Det er som om man altid udvikler et system, med den illusion for øje, at man kan nå frem til det fejlfri produkt. Når man konstaterer fejl i det leverede system betragter man det som et nederlag, men det er det kun hvis man burde have opdaget fejlen — ikke fordi den er der! Når man starter med at lave et system, bør man i virkeligheden konstatere: "Vi skal nu til at lave et system, det vil komme til at indeholde fejl, og hvis systemet stadig kører om tredive år vil det stadig have fejl — hvordan skal vi håndtere det?". Dette kapitel drejer sig om at minimere antallet af fejl i et program, men det er kun en del af løsningen. Et system skal planlægges, laves og anvendes under den forudsætning, at det ikke er fejlfrit. Man skal derfor være forberedt på fejl, så man ved hvad man skal gøre når de opstår — man skal ikke bare minimerer forekomsten af fejl, men også minimerer konsekvensen af dem der altid vil være tilbage. | ||||||
| Inden vi ser nærmere på test, der er hovedemnet for dette kapitel, vil vi kort se på andre indgangsvinkler til kvalitetskontrol. | |||||||
|
1. Kvalitetskontrol | |||||||
| Kvaliteten af et system er pr. definition, i hvor høj grad det opfylder kravspecifikationen. Test er ikke det eneste tiltag vi kan gøre i retning af at højne kvaliteten af et system. I forbindelse med test søger vi efter mangler i systemet, men ville det ikke være bedst, hvis der ikke var noget at søge efter, at vi lavede vores systemer på en sådan måde at der ikke opstod mangler? | |||||||
| Det er naturligvis lige så naivt et ønske som idéen ovenfor, om at vi vil kunne finde alle fejl. Ikke desto mindre kan vi gøre meget for at undgå mangler i vores system. Inden vi går videre i vores søgen efter fejl, vil vi derfor se hvad man kan gøre for at forebygge, så behovet for at helbrede begrænses. | |||||||
|
1.1 Metoder | |||||||
| Dyrt købte erfaringer | Hvis vi vælger metoder der bygger på sunde principper, der er udtænkt med henblik på at forebygge mangler, har vi en grundlæggende basis for at undgå senere problemer. Igennem systemudviklingens historie, siden midten af det 20. århundrede, har man prøvet mangt og meget, og man har gjort sig dyrt købte erfaringer. Det er derfor vigtigt at man vælger moderne udviklingsmetoder, der bygger på disse erfaringer. | ||||||
| Med mellemrum dukker der gyldne løsninger op, der sælges som mirakel-medicin: "Brug vores metode, så er der ingen grænse for hvilke velsignelserne, der vil regne ned over jeres projekt". Hvordan skelner man mellem sunde metoder og pop? | |||||||
| Ingen nemme løsninger | Det er i virkeligheden meget enkelt. Man kan starte med at slå fast, at der ikke er nogen nemme løsninger. I de sidste 50 år, har man måttet erkende at systemudvikling, på trods af at den er den mindste eksakte videnskab indenfor datalogien, er langt den sværest at mestre. Vi har i dag maskiner, der er meget hurtigere end for bare ti år siden, og udviklingen synes at fortsætte. Vi har lavet algoritmer der kan løse snart sagt et hvilket som helst problem. Selv indenfor kunstig intelligens har vi opnået visse resultater, selvom der er langt endnu. Men vi kan ikke lave et administrativt system til arbejdsformidlingen uden at det ender i en økonomisk katastrofe! | ||||||
| Man skal derfor bruge sin sunde fornuft når diverse metoder bliver opreklameret. Hvis grundlaget for metoden er naive eller banale læresætninger, der synes indlysende for enhver, er der fare på færde. Hvis det var så enkelt som at 2 + 2 = 4 ville vi ikke have alle de problemer vi har. Når vi derfor ser os om efter nye metoder, der skal forbedre processen og dermed produktet, er det fremskridt vi leder efter - ikke jubel-løsninger. | |||||||
| Objekt-orientering | Hvis man ikke anvender en tidsvarende metode, vil man som nævnt ikke drage nytte af de erfaringer der er gjort i de seneste år, og man er handicappet i forhold til konkurrenterne. Det seneste årtis største landvinding er de objektorienterede metoder. Det vil derfor ikke være tidsvarende at bruge f.eks. en struktureret metode, hvor man ikke får glæde af de erfaringer man har gjort mht. de objektorienterede principper, som f.eks. indkapsling og løse koblinger. | ||||||
|
1.2 Konfigurationsstyring | |||||||
| Udisciplinerede ændringer | Med konfigurationsstyring kan vi forebygge fejl, der opstår ved udisciplinerede ændringer i modellen af systemet. Mange fejl opstår ved at der foretages ændringer i dele af systemet, der ikke harmoniserer med resten af systemet. Det er derfor vigtigt hele tiden at kontrollere ændringer og deres betydning for andre delsystemer. Et moderne system vil ofte består af mange forskellige delsystemer, der vil findes i flere forskellige versioner. Konfigurationsstyring drejer sig om at holde styr på hvilke versioner af de enkelte delsystemer der kan arbejde sammen, og gøre det muligt at dokumentere disse afhængigheder. | ||||||
| Modstrid | Med konfigurationsstyring kan man undgå de fejl der opstår ved at systemet kommer i modstrid med sig selv. Det er en modstrid der viser sig ved at samarbejdet mellem de enkelte delsystemer ikke fungerer, fordi der er foretaget ændringer, hvis konsekvenser ikke er blevet realiseret i andre dele af systemet. | ||||||
|
1.3 Reviews | |||||||
| Kontrol | Reviews er effektive til at forbedre kvaliteten af produktet, men de er desværre (meget) tidskrævende og dermed også relativ dyre. Et review er en form for revision, hvor en gruppe af udviklere får "kontrolleret" deres arbejde af en anden gruppe af medarbejdere. Et review kan antage forskellige former. | ||||||
|
1.3.1 Walkthrough | |||||||
| I et walkthrough er det udviklerne der laver en formel gennemgang af de modeller de arbejder med. | |||||||
| Hvis der f.eks. er tale om implementations-modellen, kan udviklerne gennemgå kildeteksten for review'erne med en projektor. Hvis der er noget review'erne ikke forstår kan de spørge, og de kan undervejs komme med kritik og idéer til det de bliver præsenteret for. Efter review'et kan udviklerne bruge den kritik og de idéer de har fået til at forbedre implementationen. | |||||||
| Variationer |
Et walkthrough kan laves på mange forskellige måder. Nogle af de spørgsmål man kan stille sig er nemlig:
| ||||||
|
1.3.2 Inspektion | |||||||
| Formelt | Inspektion er på sin vis en slags walkthrough, men rollerne er mere eller mindre byttet om. En inspektion er en formel gennemgang af modellerne, der foretages af review'erne. De arbejder sig systematisk gennem modelerne og vurderer dem. Udviklerne kan være til stede under review'et, men det er kun for at svare på spørgsmål fra review'erne, de tager ikke del i review'et - de lytter! | ||||||
| Et eksempel på en review-metode, der bygger på inspektion, er Fagan's metode fra 1976. Den består af følgende fem trin: | |||||||
| |||||||
| Som man ser, er der en mere formel styring, end den der lægges op til i walkthrough. | |||||||
| Et review forbedrer kvaliteten af det endelige system, fordi reviewerne ser på modellerne med friske øjne. De har samtidig et andet forhold til modellerne, da de ikke er følelsesmæssigt engagerede i dem - det er ikke deres små børn, der som bekendt ikke har nogen fejl! | |||||||
| Forsvar og angreb | Et review kan let udvikle sig til et forsvar fra udviklernes side, hvor review'erne ser det som deres opgave at angribe de modeller de bliver præsenteret for. Man skal passe på ikke at overdrive en sådan udvikling, da den let bringer fokus væk fra modellerne og over på de personer der indgår i review'et. Det væsentlige er at sikre kvaliteten af modellerne, ikke at profilere sig. | ||||||
|
2. "Fejl" | |||||||
| Hvad mener vi præcist med ordet: "Fejl"? | |||||||
| På engelsk arbejder man i forbindelse med test med tre betegnelser, der alle på dansk kan oversættes med "fejl": | |||||||
| |||||||
| Selvom vi på dansk "overloader" ordet "fejl", så det anvendes til at dække flere, eller alle, af de ovenstående engelske udtryk, vil det som nævnt fremgå af sammenhængen hvad der menes. Grunden til at vi alligevel gør os den ulejlighed at foretage ovenstående opdeling, er at det giver en mere solid forståelse for hvad en fejl er. En fejl er nemlig alle tre ting! | |||||||
| Det er kravspecifikationen der bestemmer hvad der er rigtigt og forkert, det er den der bestemmer hvad der er mangler (failures), og hvad der ikke er. Når der er mangler i vores program, opdager vi dem ved at observere fejl (errors), og vi fjerner dem ved at lokalisere fejl i implementationen (faults), og rette dem. | |||||||
|
3. Test af komponenter | |||||||
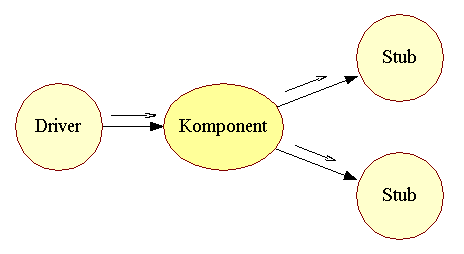
| Et komponent er i testsammenhæng en del af systemet, som kan isoleres og gøres til genstand for test. Et komponent vil normalt være et objekt eller et objektsystem som man "tager ud af systemet" og tester i simulerede omgivelser. Et komponent vil nemlig kun kunne isoleres, hvis man erstatter de dele af systemet som komponentet er lavet til at samarbejde med. I systemet vil komponentet modtage og sende requests, fra og til andre dele af systemet, og en systematisk test består i at observere komponentets adfærd i en række simulerede situationer, hvor de requests som komponentet modtager er fastlagt på forhånd. Man sammenligner den observerede adfærd med den forventede, og kan på den måde afsløre mangler ved komponentet. | |||||||
| F.eks. kunne vores test være opbygget som følger: | |||||||
| Figur 1: Komponent med driver og to stubbe |
| ||||||
| Driveren simulerer den del af systemet som sender requests til det komponent som vi vil teste, mens de to stubbe simulerer den del af systemet som komponentet sender requests til. Man kan se figur 1 som en test-opstilling svarende til den man ofte anvender i forbindelse med f.eks. elektriske komponenter. Man forbinder komponentet med en række andre komponenter, der skal simulerer det system som komponentet indgår i, og afprøver dets forskellige funktioner. | |||||||
| I en test af et komponent vil der normalt kun indgå én driver, mens antallet af stubbe afhænger af den konkrete situation. | |||||||
| Driver | Driveren vil sende nøje planlagte requests til komponentet, og man observerer dernæst komponentets adfærd: hvad det returnerer til driveren som svar på de enkelte requests. At planlægge en test består hovedsaglig i at vælge hvilke requests, man vil prøve at sende komponentet, og at dokumentere hvilke svar man forventer at få tilbage. Det er karakteristisk for systematisk test af komponenter, at man laver en lang række sammenhørende input og output. Outputet er det forventede output - det output, der iflg. komponentets kravspecifikation kendetegner en korrekt adfærd. | ||||||
| Stubbe | Stubbene simulerer de dele af systemet som komponentet anvender. De gør det ved at returnere svar til komponentet som repræsenterer mulige/sandsynlige svar som de tilsvarende komponenter i det rigtige system kunne tænkes at returnere. Stubbe laves konkret som (meget) simplificerede udgaver af de dele af systemet som de repræsenterer, f.eks. kan en stub repræsentere en del af systemet som finder telefonnummeret på en given kunde. Det rigtige system vil slå op i en større telefonbog, mens en stub f.eks. vedholdende kan påstå at telefonnummeret er 12345678 uanset hvem kunden er. | ||||||
|
3.1 Black- og whitebox-tests | |||||||
| Inden vi går videre er der et par begreber vi skal have på plads. Det er black- og whitebox-tests. Disse to testformer ser forskelligt på det komponent der skal testes. | |||||||
| Blackbox | Blackbox-tests ser på komponenten som en "lukket kasse". Man sender input ind i den ene ende og der kommer output ud af den anden. En test går ud på at bruge komponentet på en måde der tester det i forhold til kravspecifikationen. Perspektivet er, at det er ligegyldet hvad der er i kassen, bare den kan gøre det den skal. | ||||||
| Whitebox | Whitebox-tests ser anderledes på sagen. Skal man lave en god og grundig test, må man vide hvad der i "kassen", så man kan rette sine "angreb" mod de steder, der ud fra en analyse af komponentets implementation kan virke svage eller sårbare. | ||||||
| Når man arbejder med tests er det sjældent et "enten eller" i forhold til black- og whitebox-tests. Idéerne i dem begge er sunde, men ensidige. Selvfølgelig er opfyldelse af kravspecifikationen det væsentlige, men med tests kan man ikke afprøve enhver tænkelig use case, og selvfølgelig er det en forudsætning for at vi kan have tillid til komponentet, at dets indhold er solidt. | |||||||
|
3.2 Test cases | |||||||
| Udvælge | At vælge test cases er en videnskab for sig. Pålideligheden kan ses som en funktion af de test cases vi udvælger. Pålideligheden af alle mulige test cases er 100%, kunsten er at maksimere funktionen med et begrænset antal test cases! | ||||||
| Der er flere måder, hvorpå man kan udvælge disse test cases: | |||||||
|
3.2.1 Ækvivalens-test | |||||||
| Idéen i ækvivalens-test er en blackbox-test, der inddeler mængden af mulige test cases i ækvivalens-klasser. Vi kan identificere en test case entydigt ud fra dens input, og opgaven er derfor at inddele mængden af mulige input i en række delmængder. Når man konstruerer disse ækvivalens-klasser ser man på følgende egenskaber: | |||||||
| |||||||
| Opdele | Man kan lave ækvivalens-klasserne ved at tage udgangspunkt i den samlede mængde af input. Når man identificerer to input der ikke er repræsentative for hinanden, opdeler man i to mængder. Man kan på denne måde blive ved, indtil alle delmængderne er repræsentative. | ||||||
| Repræsentativ | Der lyder umiddelbart svært at lave denne opdeling, og det er det også! Idéen med ækvivalens-tests er teoretisk smuk, men ofte vanskelig i praksis. Det skyldes at det er svært at garantere, at alle input i en delmængde er repræsentative for hinanden. Testens styrke ligger i det repræsentative, da idéen er at reducere antallet af test cases ved at kunne tage én repræsentant for hver ækvivalens-klasse. På den måde blive antallet af test cases reduceret til antallet af ækvivalens-klasser. | ||||||
| Svaghed | Selvom idéen med ækvivalens-klasser er stærk, har den trods alt også svagheder. F.eks. er det ikke muligt at teste kombinationer af input, hvor fejl kan opstå som følge af, at et objekt befinder sig i en tilstand efter at have modtaget en tidligere request. Mao. ækvivalens-tests er meget funktionelt orienteret. | ||||||
|
3.2.2 Boundry-test | |||||||
| Boundry-test er en specialisering af ækvivalens-test; hvor man ikke nøjes med én repræsentant fra en delmængde. Idéen er at man ikke helt stoler på at alle input i delmængderne er repræsentative, og dermed ikke, at de er rigtige ækvivalens-klasser. | |||||||
| Man vælger derfor at tage repræsentanter fra "kanten" af den delmængde man er nået frem til. Det gør man ud fra den betragtning at udviklerne ofte overser specialtilfælde på grænsen af de (næsten) ækvivalens-klasser man når frem til. | |||||||
| Betegnelsen "kanten" er naturligvis ikke særlig konkret. Det vil i praksis ofte dreje sig om grænseværdier i intervaller, og specialtilfælde: | |||||||
| |||||||
| Ligesom ækvivalens-testen kan boundry-testen ikke finde fejl, der skyldes kombinationer af input. | |||||||
|
3.2.3 Path-test | |||||||
| I modsætning til ækvivalens- og boundry-testen er path-testen en whitebox-test. Man tager udgangspunkt i flowgrafen for implementationen man vil test. Idéen er at lave en test case for hver mulig sti fra startknuden til enhver slutknude i denne graf og på den måde dække samtlige mulige forløb i implementationen. | |||||||
| statement-test | En sådan test er meget grundig, og det kan være udfordrende at finde input, der afprøver samtlige mulige stier i flowgrafen. Derfor ser man ofte at der i stedet anvendes en variant af path-test, der kræver færre test cases: statement-test. Idéen i en statement-test, er at alle sætninger i implementationen bliver udført. På den måde skal man ved valg af test cases kun sikre sig, at man kommer ud i alle hjørner af implementationen - det er nu ikke længere væsentligt hvilke sætninger der bliver udført før og efter en given sætning, blot de hver især bliver udført i forbindelse med en test case. | ||||||
|
3.3 Problemer med objekter og komponent-test | |||||||
| Der er en række problemer i forbindelse med komponent-test af objekter og objektsystemer. | |||||||
|
3.3.1 Tilstande | |||||||
| Ignoreres | Det største problem er, at et objekt har en tilstand. Idéen med at en test case er en kombination af et input og et forventet output er meget funktionelt orienteret, og ignorerer fuldstændig at objektet kan opføre sig forskelligt alt efter hvilken tilstand det befinder sig i. Det er flere gange nævnt ovenfor at diverse test ikke kan håndtere kombinationer af input, og netop forskellige kombinationer af input kan bringe objekter i forskellige tilstande, så det samme input ikke altid giver det samme output. Det betyder at man i virkeligheden ikke kan tale om et forventet output. | ||||||
| Forventet tilstand | Vi kan ikke længere nøjes med et input, men må også fastlægge en bestemt start-tilstand. Det samme gør sig gældende for output. Output'et bliver nemlig ikke det eneste interessante i forbindelse med kaldet af en metode. Vi er også interesseret i hvilken tilstand objektet er i efter kaldet, og derfor kommer også en forventet tilstand ind i billedet. | ||||||
| Indkapsling | Hvordan sætter man et objekts tilstand før man udfører en test case, og hvordan sammenligner man en forventet tilstand med en observeret, hvis man ikke kan tilgå tilstanden pga. indkapsling? Det er vanskeligt! | ||||||
| Vores kvaler er dog ikke gjort alene med det! | |||||||
|
3.3.2 Polymorfi | |||||||
| Flere implemen-tationer | Hvilken implementation af metoden er det vi kalder? Hvis en metode er polymorf er svaret ikke så enkelt. Det er nogenlunde enkelt at afprøve alle subklasser med de samme test cases, men hvad hvis polymorfien "gemmer sig" inde i et objektsystem, og der evt. er flere forskellige steder i objektssystemet der optræder polymorfi. | ||||||
| Mere komplekst | Problemet er ikke, at vi ikke kan foretage en test - problemet er, at det lige pludselig er blevet en meget større opgave. Der er mange ting der skal prøves i kombination med hinanden, og de tests der var gode i forbindelse med én implementation er måske ikke repræsentative i forbindelse med en anden. | ||||||
| Vi har nu haft fat i de to værste problemer, men det er ikke slut! | |||||||
|
3.3.3 Delegering | |||||||
| Hvor? | Funktionalitet i et objektsystem er ofte distribueret ud på flere objekter, der samarbejder om at løse et problem. Det betyder at metoderne ofte er små, og at algoritmer implementeres som en (lang) række af kald fra objekt til objekt. Når vi observerer en fejl, hvor skal vi så finde den. Ligger fejlen i samarbejdet mellem objekterne eller kan det isoleres til et objekt? | ||||||
| Svært | Som man kan se er problemerne i forbindelse med objektorienterede programmer både flere og mere komplekse, og udviklernes opgave med at lave gode test cases er bestemt ikke en let byrde. | ||||||
|
4. Hvem tester? | |||||||
| Hvem? | Spørgsmålet lyder måske lidt naivt, for vi skal jo alle teste, men så enkelt er det ikke! | ||||||
| Os? | Hvem er den bedste til at teste det arbejde vi laver? - Os selv? - Næppe! | ||||||
| Som det blev nævnt i forbindelse med reviews kan den menneskelige faktor gøre det uhensigtsmæssigt at man selv kontrollerer sit arbejde, og dermed det produkt man udvikler. Når man tester drejer det sig ikke om at bekræfte at systemet virker, for det kan man alligevel ikke — det drejer sig om at presse systemet til det yderste, og helst lidt længere. Kun på den måde kan man få klemt så mange fejl ud af systemet, at det bliver pålideligt. | |||||||
| Rengøring | Man kan sammenligne det med at gøre rent. Personligt betragter jeg ikke rengøring som det primære formål med min eksistens, og det er da også kun få der kan lide at gøre rent. Til gengæld er det nødvendigt, på samme måde som test også er drevet af nødvendigheden. | ||||||
| Når man gør rent kan man gøre det på to måder. Man kan nøjes med at gøre det nødvendige, at foretage en rengøring der er tilstrækkelig til at et lokale kan anvendes til det formål det er beregnet til. Det er denne form for rengøring, der begrænser glæden ved at opholde sig i et lokale med mindre man er nød til det. Der er også en anden form for rengøring — det er den der søger at gøre pinlig rent, den bestræber sig til det yderste for at fjerne enhver form for snavs. | |||||||
| Pålideligt | Selvom den sidste form for rengøring ikke altid er hensigtsmæssig, da tingene jo hurtigt kan blive beskidte igen, er det alligevel denne form for rengøring der skal inspirere os når vi søger efter fejl. Vi skal gøre vores yderste for at få udryddet det sidste "snavs", så vores system kan fremstå som pålideligt! |